

Sameer Gaikwad web developer HTMLCSS/jQuery/angular/react
Basic .Net Interview Questions
1. What is .NET?
Ans:.NET is a free, open-source, cross-platform framework developed by Microsoft that allows developers to build a wide range of applications, including web applications, desktop applications, mobile apps, gaming applications, and more. It provides a consistent programming model, extensive class libraries, and a runtime environment for executing applications
2. What is the .NET framework?
Ans: The Common Language Runtime (CLR) manages memory, performs garbage collection, handles exceptions, and provides other runtime services. It also supports features like type safety, automatic memory management, and just-in-time (JIT) compilation of code.
Application Types: The .NET Framework supports building various types of applications, including:
- Windows Forms: Traditional desktop applications with graphical user interfaces (GUI).
- WPF (Windows Presentation Foundation): Rich desktop applications with advanced UI capabilities.
- ASP.NET Web Forms: Web applications that follow a form-based, event-driven programming model.
- ASP.NET MVC (Model-View-Controller): Web applications that follow the MVC architectural pattern.
- Console Applications: Text-based applications that run in a console window.
- Windows Services: Background services that run on a Windows machine.
- Class Libraries: Reusable libraries that can be used by other .NET applications.
3. What languages does the .NET Framework support?
Ans: .NET Framework supports over 60 programming languages, out of these 11 programming languages are designed and developed by Microsoft.
4. What are the most important aspects of .NET?
Ans: .NET is an open-source platform containing around 32 programming languages and several tools for application creation. It is highly secure and runs comfortably on multiple computer platforms.
5. Explain OOP and its relation to the .NET Framework?
Ans: Object-Oriented Programming (OOP) is a programming paradigm that organizes software design around objects, which are instances of classes. It emphasizes the concepts of encapsulation, inheritance, and polymorphism to enable modular, reusable, and maintainable code.
The .NET Framework is closely aligned with the principles of OOP and provides extensive support for implementing OOP concepts. Here's how OOP relates to the .NET Framework:
- Classes and Objects: In OOP, a class is a blueprint that defines the structure and behavior of an object. It encapsulates data (attributes) and methods (behavior) related to the object. The .NET Framework provides a class-based object model, allowing developers to define classes and create objects based on those classes. Classes in the .NET Framework can be used to model entities, represent data, implement business logic, or provide functionality.
- Encapsulation: Encapsulation is the principle of bundling data and related methods within a class, hiding the internal implementation details from the outside world. The .NET Framework supports encapsulation through access modifiers like public, private, protected, and internal, allowing developers to control the visibility and accessibility of class members. Encapsulation helps in achieving code organization, modularity, and information hiding.
- Inheritance: Inheritance is a mechanism in which one class inherits properties and behaviors from another class. It enables the creation of a hierarchy of classes, where derived classes inherit and extend the functionality of a base class. The .NET Framework supports single inheritance, allowing a class to inherit from a single base class. Inheritance promotes code reuse, extensibility, and the implementation of the "is-a" relationship between classes.
- Polymorphism: Polymorphism allows objects of different classes to be treated as objects of a common base class. It enables methods to be defined in a base class and overridden in derived classes with their own specific implementations. The .NET Framework supports polymorphism through virtual and override keywords, allowing developers to define and invoke methods based on the actual type of the object at runtime. Polymorphism helps in achieving code flexibility, extensibility, and the implementation of the "one interface, multiple implementations" concept.
- Abstraction: Abstraction is the process of representing complex real-world entities as simplified models in code. It involves identifying and capturing the essential characteristics of an object, while hiding unnecessary details. The .NET Framework provides abstraction mechanisms such as abstract classes, interfaces, and delegates. Abstract classes and interfaces allow developers to define contracts and common behavior, while delegates enable function pointers and event handling. Abstraction promotes modularity, loose coupling, and separation of concerns.
6. What are the basic features of OOP?
Ans: The basic features of OOP are:
- Encapsulation: Creation of self-contained modules that bind together the data and the functions that access that data.
- Abstraction: Handles complexity and allows the implementation of further complex logic without disclosing it to the user object.
- Polymorphism: The operation performed depends upon the context at runtime to facilitate easy integration.
- Inheritance: Creation of classes in a hierarchy to enable a class to inherit behavior from its parent class allowing reuse of code.
7. Name some OOP languages?
Ans: Simula was the first OOP language and Java, JavaScript, Python, C++, Visual Basic. NET, Ruby, Scala, PHP are few others.
8. What is JIT?
Ans: JIT stands for Just In Time. It is a compiler in CLR responsible for the execution of .NET programs of different languages by converting them into machine code. It speeds up the code execution and supports multiple platforms.
9. What are the different types of JIT Compilers?
Ans: There are 3 types of JIT Compilers:
i. Pre-JIT compiler: It compiles all the source code into the machine code in a single compilation cycle, i.e. at the application deployment time.
ii. Normal JIT Compiler: The source code methods required at run-time are compiled into machine code and stored in the cache to be called later.
iii. Econo JIT Compiler: The methods required only at run-time are compiled using this compiler and they are not stored for future use.
10. What is BCL?
Ans: BCL stands for Base Class Library. It comprises classes, interface, and value types. It is the foundation for building .NET Framework applications, components, and controls.
11. What is FCL?
Ans: FCL stands for Framework Class Library and is a collection of reusable types, including classes, interfaces, and data types included in the .NET Framework. It is used for developing a wide variety of applications, as it provides access to system functionality.
12. What is caching in .NET?
Ans: Caching functionality in .NET Framework allows data storage in memory for rapid access. It helps improve performance by making data available, even if the data source is temporarily unavailable, and enhances scalability.
13. What are the types of caching in .NET?
- Ans: Output Caching: Output caching is a technique where the generated output of a web page or a portion of it is cached on the server and served to subsequent requests without re-executing the code that generates the output. It can be applied to individual pages or user controls to cache the rendered HTML output. Output caching can significantly improve the response time and reduce server load.
- Data Caching: Data caching involves storing frequently accessed data in memory to avoid repeated database queries or expensive calculations. The .NET Framework provides the System.Runtime.Caching namespace, which offers classes like MemoryCache and ObjectCache for caching data in memory. Developers can cache the results of database queries, API responses, or any other computationally expensive data to reduce latency and improve application performance.
- Fragment Caching: Fragment caching is similar to output caching but is applied to specific portions or fragments of a web page instead of the entire page. It allows caching only the parts that are dynamic or computationally expensive, while the rest of the page is generated normally. Fragment caching can be useful when specific sections of a page need to be cached while keeping other parts dynamic.
- In-Memory Caching: In-Memory caching involves storing frequently accessed data in memory for faster retrieval. It is commonly used for caching small to medium-sized data sets that need to be accessed frequently. In .NET, the MemoryCache class from the System.Runtime.Caching namespace is often used for in-memory caching. In-memory caching is efficient for data that doesn't need to be persisted beyond the application's lifetime.
- Distributed Caching: Distributed caching involves caching data across multiple servers or nodes to improve scalability and performance in distributed environments. It allows multiple instances of an application to share a common cache, reducing the load on backend resources. .NET provides several distributed caching solutions, such as Redis Cache, Microsoft Azure Cache for Redis, and AppFabric Caching, which can be used to implement distributed caching scenarios.
- ASP.NET Session State Caching: ASP.NET provides session state caching to store session data in memory instead of relying on the default out-of-process or database-based session storage. By caching session data in memory, it reduces the overhead of accessing the external storage for every session operation, improving session performance.
14. What is a cross-page posting?
Ans: Cross-page posting is used to submit a form to a different page while creating a multi-page form to collect information from the user. You can specify the page you want to post to using the PostBackURL attribute.
15. Discuss the difference between constConstant fields are created using the const keywoogram. The Read-only fields are created using a read-only keyword and thed. Const is a compile-time constant while Read-only is a runtime
- Value types hold the actual data values themselves.
- They are stored directly in memory wherever they are declared or assigned.
- Examples of value types include primitive types like integers (int), floating-point numberstypes store a reference (memory address) to the location where the actual data is stored.
- They are stored on the heap, which is a region of memory used for dynamic memory allocation.
- Examples of reference types include classes, strings (string), arrays, and delegates.
- When a reference type is assigned to a new variable or passed as an argument to a method, only the reference to thtions made through one reference will affect all other references to the same object.
- Reference types have a dynamic size as they can grow or shrink during runtime based on the size of the actual data they represent.
- Memory management for reference types is handled by garbage collection, where unused objects are automatically identified and reclaimed by the runtime.
17. What are EXE and DLL?
Ans: EXE is an executable file that works as an application and it runs individually as it contains an entry point. DLL is a Dynamic Link Library which is a supportive file to other applications, and it cannot run individually.
18. What is the difference between Stack and Heap?
Ans: The stack is used for static memory allocation and access to this memory is fast and simple to keep track of. Heap is used for dynamic memory allocation and memory allocation to variables that happen at run time. Accessing the heap memory is complex and slower compared to the stack.
19. What is the difference between Stack and Queue?
Ans: The values in a stack are processed following the LIFO (Last-In, First-Out) principle, so all elements are inserted and deleted from the top end. But a queue lists items on a FIFO (First-In, First-Out) basis in terms of both insertion and deletion. The elements are inserted from the rear end in a queue and deleted from the front end.
20. What are the differences between systems. StringBuilder and system. string?
Ans: System. a .string is immutable and fixed-length, whereas StringBuilder is mutable and variable length. The size of the .string cannot be changed, but that of the .stringbuilder can be changed.
Advanced .Net Interview Questions
21. What is the difference between the While and For loop? Provide a .NET syntax for both loops?
Ans: The For loop provides a concise way of writing the loop structure, but the While loop is a control flow statement that allows repetitive execution of the code. Initialization, condition checking, iteration statements are written at the top of the For loop, but only initialization and condition checking is done at the top of the while loop.
Syntax:
While loop:
while(condtion) {
//statements to excute.
}
For loop:
for(intialization; condition; Increment or decrement){
// statements to be excuted.
}22. What are a base class and derived class?
Ans: The base class is a class whose members and functions can be inherited, and the derived class is the class that inherits those members and may also have additional properties.
23. What is the extension method for a class?
Ans: The extension method is used to add new methods in the existing class or structure without modifying the source code of the original type. Special permission from the original type or re-compiling it isn’t required.
24. What is inheritance?
Ans: Inheritance is a method for creating hierarchies of objects wherein one class, called a subclass, is based on another class, called a base class.
25. What is the inheritance hierarchy?
Ans: Inheritance hierarchy is a singly rooted tree structure for organizing classes.
26. What are implementation inheritance and interface inheritance?
Ans: Implementation inheritance is when a class inherits all members of the class from which it is derived. Interface inheritance is when the class inherits only signatures of the functions from another class.
27. How can a class be prevented from being inherited?
Ans: To prevent a class from being inherited, the sealed keyword in C# can be used. The NotInheritable keyword can be used in VB.NET to prevent accidental inheritance of the class.
28. What is a constructor in C#?
Ans: A constructor is a special method of the class that contains a collection of instructions and gets automatically invoked when an instance of the class is created.
29. Explain Different Types of Constructors in C#?
Ans: There are 5 types of constructors in C#, as given below:
- Default Constructor: It is without any parameters.
- Parameterized Constructor: It has one parameter.
- Copy Constructor: It creates an object by copying variables from another object.
- Static Constructor: It is created using a static keyword and will be invoked only once for all of the instances of the class.
- Private Constructor: It is created with a private specifier and does not allow other classes to derive from this class or create an instance of it.
30. Define Method Overriding?
Ans: Method Overriding is a process that allows using the same name, return type, argument, and invoking the same functions from another class (base class) in the derived class.
31. What is Shadowing?
Ans: Shadowing makes the method of the parent class available to the child class without using the override keyword. It is also known as Method Hiding.
32. What is the difference between shadowing and overriding?
Ans: Shadowing is used to provide a new implementation for the base class method and helps protect against subsequent base class modification. Overriding allows you to rewrite a base class function with a different definition and achieve polymorphism.
33. What is Polymorphism?
Ans: Polymorphism refers to one interface with multiple functions. It means that the same method or property can perform different actions depending on the run-time type of the instance that invokes it.
34. What are the types of Polymorphism?
Ans: There are two types of Polymorphism:
i. Static or compile-time polymorphism
ii. Dynamic or runtime polymorphism
35. Do we have multiple inheritances in .NET? Why?
Ans: No, .NET supports only single inheritance due to the diamond problem. Also, it would add complexity when used in different languages. However, multiple interfaces can solve the purpose.
36. What is the Diamond of Death?
Ans: It is an ambiguity that arises due to multiple inheritances in C#. Two classes B and C inherit from A, and D inherits from both B and C but doesn’t override the method defined in A. The Diamond Problem arises when class B or C has overridden the method differently and D cannot decide to inherit from either B or C.
37. What is an Interface?
Ans: An interface is a declaration for a set of class members. It is a reference type that contains only abstract members such as Events, Methods, Properties, etc.
38. What are the events and delegates?
Ans: Events notify other classes and objects when the desired action occurs in a class or object. A delegate is a type-safe function pointer that defines a method signature in CLI.
39. What is business logic?
Ans: It is the application processing layer that coordinates between the User Interface Layer and Data Access Layer.
40. What is the difference between a component and a control?
Ans: A Component does not draw itself on the form and can be placed below the form area. A control draws itself on the form and can be placed inside the form area. Also, all controls are components, but not all components are controls.
41. Differentiate between user controls and custom controls?
Ans: User and Custom controls inherit from different levels in the inheritance tree. Custom control is designed for use by a single application while user control can be used by more than one application.
42. What are the functional and non-functional requirements?
Ans: Functional requirements are the basic and mandatory facilities that must be incorporated into a system. Non-functional requirements are quality-related attributes that the system must deliver.
43. What is .Net Reflection?
Ans: Reflection objects are used for creating type instances and obtaining type information at runtime. The classes in the System.Reflection namespace gives access to the metadata of a running program.
44. What is the Global Assembly Cache (GAC)?
Ans: The Global Assembly Cache is a machine-wide code cache that is stored in a folder in the Windows directory. It stores the .NET assemblies that are specifically designated to be shared by all applications executed on the system.
45. What is Object-Role Modeling (ORM)?
Ans: Object-Role Modeling (ORM) is a powerful method for designing and querying information systems at the conceptual level. It is an easy and understandable description of the application for non-technical users.
46. What are globalization and localization?
Ans: Globalization is designing and coding culture-neutral and language-neutral applications. Localization is customizing the application and translating the UI based on specific cultures and regions.
47. What is MIME?
Ans: MIME stands for Multipurpose Internet Mail Extension. It is an add-on or a supplementary protocol that allows non-ASCII data to be sent through SMTP. It facilitates the exchange of data files on the internet and was proposed by Bell Communications in 1991.
48. What is a Hashtable?
Ans: The Hashtable class is a collection that stores key-value pairs. It organizes the pairs based on the hash code of each key and uses it to access elements in the collection.
49. Name design patterns in the .NET Framework?
Ans: There are 23 design patterns classified into 3 categories:
1. Creational Design Pattern
i. Factory Method
ii. Abstract Factory
iii. Builder
iv. Prototype
v. Singleton
2. Structural Design Patterns
i. Adapter
ii. Bridge
iii. Composite
iv. Decorator
v. Façade
vi. Flyweight
vii. Proxy
3. Behavioral Design Patterns
i. Chain of Responsibility
ii. Command
iii. Interpreter
iv. Iterator
v. Mediator
vi. Memento
vii. Observer
viii. State
ix. Strategy
x. Visitor
xi. Template Method
.Net Interview Questions for Experienced
50. What are the design principles used in .NET?
Ans: Net uses the SOLID design principle which includes the following:
- Single responsibility principle (SRP)
- Open-Closed Principle (OCP)
- Liskov substitution principle (LSP)
- Interface segregation principle (ISP)
- Dependency inversion principle (DIP)
51. What is Marshaling?
Ans: Marshaling is the process of transforming types in the managed and unmanaged code.
52. What are Boxing and Unboxing?
Ans: Boxing and Unboxing is a concept of C#, which enables a unified view of the type system to treat the value of any type as an object.
53. What is the difference between Server. Transfer and Response. Redirect?
Ans: These are used to redirect a user from one web page to the other one. The Response. The redirect method requests a new URL and specifies the new URL. The Server. The transfer method terminates the execution of the current page and starts the execution of a new page.
54. What is Garbage Collection in .NET?
Ans: Garbage Collection in .NET Framework facilitates automatic memory management. It automatically releases the memory space after all the actions related to the object in the heap memory are completed.
55. What are the divisions of the Memory Heap?
Ans: The memory heap is divided into three generations.
Generation 0: Used to store short-lived objects. Frequent Garbage Collection happens in this Generation.
Generation 1: Used for medium-lived objects.
Generation 2: Used for long-lived objects.
56. What is the difference between the trace class and debug class?
Ans: The call to Debug class is included in Debug mode only and it is used at the time of application development. While the call to Trace class will be included in Debug as well as Release mode also and it is used at the time of application deployment.
57. Differentiate between a Debug build and a Release build?
Ans: Debug builds do not optimize and allow the accurate setting of breakpoints. They contain debugging symbols, but the code built-in "Release" mode is optimized for speed or size without any debug data.
58. What is the application object?
Ans: The Application object is used to share information among all users of an application. You can tie a group of ASP files that work together to perform some purpose.
59. What is the session object?
Ans: A Session object stores information and variables about a user and retains it throughout the session.
60. What are managed and unmanaged codes?
Ans: Managed code runs inside CLR and installing the .NET Framework is necessary to execute it. Unmanaged code does not depend on CLR for execution and is developed using languages outside the .NET framework.
61. How is a Managed code executed?
Ans: The steps for executing a managed code are as follows:
- Choose a language compiler depending on the language of the code.
- Convert the code into an Intermediate language using its own compiler.
- The IL is then targeted to CLR which converts the code into native code using JIT.
- Execution of Native code.
62. What are the different parts of an Assembly?
Ans: The different parts of an Assembly are:
i. Manifest: Also known as the assembly metadata, it has information about the version of an assembly.
ii. Type Metadata: Binary information of the program.
iii. MSIL: Microsoft Intermediate Language code.
iv. Resources: List of related files.
63. What is MVC?
Ans: MVC is an architectural model for building .Net applications. It stands for Model View Controller. It is easy to use and offers full control over the HTML.
64. Explain the difference between Function and Stored procedure?
Ans: Stored Procedures are pre-compiled objects which execute the code when called for. While a Function is compiled and executed when it is called for.
65. What is a .NET web service?
Ans: It is a component that allows the publishing of the application's function on the web to make it accessible to the public. It resides on a Web server and provides information and services using standard Web protocols such as HTTP and Simple Object Access Protocol (SOAP).
66. What are the advantages of Web Services?
Ans: The advantages of Web Services are:
- It is simple to build and supported by a variety of platforms.
- It can extend its interface and add new methods without affecting the client's operations.
- It is stateless and firewall-friendly.
67. What is MEF?
Ans: MEF stands for Managed Extensibility Framework. It is a library that allows the host application to consume external extensions without any configuration requirement.
68. What are Tuples?
Ans: Tuples are data structures that hold object properties and contain a sequence of elements of different data types. They were introduced as a Tuple<T> class in .NET Framework 4.0 to avoid the need of creating separate types to hold object properties.
69. What is ADO?
Ans: ADO stands for ActiveX Data Objects. It is an application program for writing Windows applications. It is used to get access to a relational or non-relational database from database providers such as Microsoft and others.
70. What are the fundamental objects in ADO.NET?
Ans: There are two fundamental objects in ADO.NET:
i. DataReader: connected architecture.
ii. DataSet: disconnected architecture.
71. What is Object Pooling?
Ans: Object Pooling is a concept for optimal use of limited resources through software constructs. The ready-to-use objects, connections, and threads are stored in a pool (group) of objects in memory for later use. For creating a new object, it is pulled from the pool and allocated for the request. Pooling helps in improving performance and facilitates scalability.
72. What are client-side and server-side validations in Web pages?
Ans: Client-side validations take place at the client end with the help of JavaScript and VBScript offering a better user experience. The inputs for client-side validation are validated in the user’s browser. While, server-side validations take place at the server end using ASP.Net and PHP, the feedback is sent through a dynamically generated new webpage.
73. What is Serialization?
Ans: Serialization is the process of converting the state of an object into a form (a stream of bytes) to be persisted or transported. Deserialization converts a stream into an object and is the opposite of serialization. These processes allow data to be stored and transferred.
74. What is a PE file?
Ans: PE stands for Portable Executable. It is a derivative of the Microsoft Common Object File Format (COFF). Windows executable. EXE or DLL files follow the PE file format. It consists of four parts:
1. PE/COFF headers: Contains information regarding. EXE or DLL file.
2. CLR header: Contains information about CLR & memory management.
3. CLR data: Contains metadata of DDLs and MSIL code generated by compilers.
4. Native image section: Contains sections like .data, .rdata, .rsrc, .text, etc.
75. What is the difference between DLL and EXE?
Ans: .EXE files are single outbound files that cannot be shared with other applications. DLL files are multiple inbound files that are shareable.
76. What is the difference between dataset.clone and dataset. copy?
Ans: Dataset.clone copies only the structure of the DataSet which includes all DataTable schemas, relations, and constraints but it does not copy any data. Dataset. copy is a deep copy of the DataSet that duplicates both its structure and data.
77. Describe the use of ErrorProvider Control in .NET?
Ans: The ErrorProvider control is used to indicate invalid data or errors to the end-user while filling a data entry form. In case of invalid data entry, the error message attached to the error description string is displayed next to the control.
78. Differentiate between Task and Thread in .NET?
Ans: The thread represents an actual OS-level thread, with its own stack and kernel resources, and allows the highest degree of control. You can choose to Abort() or Suspend() or Resume() a thread, and set thread-level properties, like the stack size, apartment state, or culture. While a Task class from the Task Parallel Library is executed by a TaskScheduler to return a result and allows you to find out when it finishes.
79. .NET is an OOP or an AOP framework?
Ans: NET is an OOP framework as Encapsulation and Inheritance is key features of the Object-Oriented Programming framework.
80. What is Multithreading?
Ans: Multi-threading is a process that contains multiple threads each of which performs different activities within a single process. .NET supports multithreading in two ways:
- Starting threads with ThreadStart delegates.
- Using the ThreadPool class with asynchronous methods.
web developer web developer
1. What is the difference between SOAP and REST?
| SOAP | REST |
| A Web Development protocol | An architectural platform |
| Works with XML | Works with XML, HTML, and plain text |
| SOAP cannot use REST | REST can make use of SOAP |
2. What is the use of a namespace in Web Development?
A namespace is a simple global object that is used to hold methods, properties, and other objects in them. It adds ease of use via modularity, thereby, providing users with the ability to reuse the code and avoid naming conflicts.
3. What are the newly introduced input types in HTML5?
HTML5 has had multiple revamps in the past years, and the addition of input types has made it very easy to work with. Some of these input types are as follows:
- color
- date
- Datetime-local
- month
- number range
4. What are the five elements that support media content in HTML5?
There are five main elements in HTML5 that support media:
- <audio>
- <video>
- <source>
- <embed>
- <track>
5. What is SVG and why is it used?
SVG stands for Scalable Vector Graphics. It is used to display vector-based graphics over the web. The graphical content it can render is based on an XML format. With SVG, the graphical content is of superior quality thereby providing the user with the ability to furnish high-quality images.
6. What is the use of Canvas in HTML?
Canvas was added onto HTML5 to give users the ability to draw graphics on the go, using JavaScript. There are a variety of methods in <canvas> to allow for the drawing of paths, circles, boxes, images, and more.
Next up on this top Web Developer interview questions and answers, let us understand the difference between canvas and SVG.
7. What is the difference between Canvas and SVG?
| Canvas | SVG |
| Resolution dependant | Resolution independent |
| Does not support event handlers | Supports event handlers |
| Works well for small-scale rendering applications | Performs better for large-scale rendering applications |
8. How can page loading time be reduced?
There are many factors that affect the page loading time of a website. However, some methods can be implemented to reduce it drastically. They are given below:
- Reduction in the image size
- Removal of unnecessary widgets
- HTTP compression
- Reduction in lookups
- Minimal redirection and caching
9. What is the use of CORS?
CORS stands for Cross-origin Resource Sharing. It is a mechanism that allows a variety of resources to be requested at a time from a domain that is outside the current request domain.
The next web application interview question comprises an important difference. Check it out below.
10. What is the difference between localStorage and sessionStorage objects?
| localStorage | sessionStorage |
| No expiry is there for stored data | The object is valid for only a single session |
| Data is not deleted upon the closure of the window | The object is immediately deleted upon closing the window |
11. What are some of the new features that are introduced in CSS3?
CSS3 has brought about a lot of changes, making the overall framework more user-friendly and powerful. Some of the features that were added and are very popularly used now are:
- Rounded corners
- Animation
- Custom layout
- Media queries
12. What is Responsive Web Design (RWD) in HTML and CSS?
Responsive Web Design is a concept that is used to create web pages that can scale across multiple resolutions without any loss of information or screen tearing.
It automatically adjusts the structure of the web page based on the device it is viewed on to provide optimal viewing experience.
13. What are some of the types of CSS that are used?
There are three main types of CSS present:
- Inline CSS: Supports the addition of CSS inline, alongside HTML elements
- External CSS: Used to import an external CSS file to the HTML document
- Embedded CSS: Used to add CSS styles by making use of the <style> attribute
14. What is the use of a selector in CSS?
A CSS selector is used with a rule in the inline elements, which require styling. With the help of selectors, it is easy to find and select HTML elements based on factors, such as name, ID, attribute, etc.
15. Can you give an example of using an ID selector in CSS?
The ID selector is used in CSS to point to a target element for usage. It is denoted in the following example:
#example {padding: 20px;}
<p id="SelectorExample">
...
</p>
16. What is the use of grouping in CSS3?
Grouping is used in CSS3 to give users the ability to reuse and apply the same CSS style element to multiple HTML entities, using just one single declaration statement.
A simple example of grouping is as shown below:
#grouped g, ul { padding-top: 20px; margin: 1; }
17. What is the use of a class selector in CSS?
Class selectors in CSS begin with a “.” (period) key and are followed by the name of the class. It is used to select a statement and modify the style of that element in the corresponding part of the HTML tag.
Consider the following example:
.exampleclass {font-family: TimesNewRomanl; font-size: 20; background: red;}
<div class="sampleclass">
...
</div>
Next up on these web technologies interview questions, let us understand a little about the use of Webkit.
18. What is the use of Webkit in CSS3?
Webkit is an important software component in CSS that allows for the easy rendering of HTML and CSS elements in a variety of browsers, such as Chrome, Firefox, and Safari.
There are many engines for browsers such as:
- Gecko for Mozilla
- Presto for Opera
- Edge for Internet Explorer
19. What are the uses of child selectors in CSS?
Child selectors are primarily used in CSS to look up the ‘child’ component of an element in CSS.
Consider an example where the <ul> tag is used in a paragraph. Then, the ‘ul’ tag becomes a child of the paragraph element. To implement this in CSS, the following syntax is used:
p > ul { font-size:20px; }
Next up on this top Web Developer interview questions and answers blog, let us take a look at the intermediate set of questions.
20. How does CSS3 help in implementing rounded borders easily?
CSS3 has the <border-radius> property that allows elements to be created with nice-looking rounded corners. This can easily be applied to all four sides or as per requirement.
The <border-radius> property has four attributes for four corners:
- <border-top-left-radius>
- <border-top-right-radius>
- <border-bottom-left-radius>
- <border-bottom-right-radius>
21. What is pagination? How can pagination be implemented?
Pagination is a simple sequence of pages on a website. These pages are interconnected and have similar content to display to the users.
A simple example is the page selector on an e-commerce site that allows the users to browse through the products present on multiple pages rather than scrolling up and down on one single page.
It can easily be implemented in CSS3 using the following code:
<div class="main_container"> <div class="pagination"> <ul> <li><a href="#"></a></li> <li><a href="#"></a></li> <li class="active"><a href="#"></a></li> <li><a href="#"></a></li> </ul> </div> </div>
22. What are the components of the CSS box model?
The CSS box model is used to represent an entity that encloses all of the HTML content into a box or a button element.
There are four components:
- Border: Denotes the padding and content around the border
- Content: Refers to the actual content to be displayed
- Margin: Refers to the top layer of the box element
- Padding: Defines the empty space around the element
23. What are some of the properties of transitions in CSS3?
Transitions in CSS3 are easy to use, and they provide users with rapid and efficient animation effects.
The four main properties present in the transitions are:
- transition-delay
- transition-duration
- transition-property
- transition-timing-function
24. What is the use of pseudo-classes in CSS?
Pseudo-classes are used as a popular technique in CSS to change the style of an element when this element changes its state.
There are numerous examples of when you use a pseudo-class:
- For the style change when the mouse moves over the element
- For out-of-focus animations
- For providing styles for external links
We have to understand media queries in the next set of interview questions for web developers. Let’s check it out.
25. What is the use of media queries in CSS3?
Media queries are used to define styles in CSS, which are responsive based on a variety of shapes and sizes of the viewing window.
They are used to adjust the following entities:
- Height
- Width
- Viewport
- Resolution
- Orientation
26. Why is float used in CSS?
Float is a popular property in CSS to control the layout and position of an element on a web page.
Any element can be placed on the web page as per requirement. Consider the following example:
div { float: right; }
Here, the contents of div will be placed on the right side of the screen.
27. What is z-index in CSS?
Z-index is a property in CSS that is used to define the order of elements on a web page. It works on the basis of order indices, where a higher-order element will appear before a lower-order element.
It only applies to elements that are positioned, i.e., those elements having the position attribute compulsorily.
Consider the following example:
div {
position: fixed;
left: 15px;
top: 20px;
z-index: -1;
}
28. Why are external style sheets preferred?
External style sheets provide an ample amount of advantages to developers. Some of the benefits are as follows:
- Classes can be reused any number of times.
- They allow for the style control of multiple documents through a single file.
- Selectors and grouping can be used to apply styles easily.
29. What is the meaning of long polling in Web Development?
Long polling is a development pattern that is used to emulate a data push operation from a server to a client machine.
When long polling is operational, the client sends in a request to the server, and the data is pushed. The connection will timeout only when the data is sent to the client or after the timeout criteria are met.
31. What is the difference between cookies and local storage?
| Cookies | Local Storage |
| Cookie data is accessible for both the client and the server | Data is stored only on the local browser in the client-side machine |
| Cookies have an expiry time, and data gets deleted post expiration | There is no expiry in local storage unless the data is manually deleted |
In the next set of interview questions for web developers, we have a very important question regarding HTML and XHTML.
32. What is the difference between XHTML and HTML?
| XHTML | HTML |
| Tags should be in lowercase | It is not case sensitive |
| Tags should be closed once opened | Open-ended tags can be used |
| Attributes must be enclosed in double quotes | Attributes can be used without quotation marks |
33. What are the various data types present in JavaScript?
JavaScript supports the following data types:
- Boolean
- Number
- Object
- Undefined
- Null
- String
- Function
34. How can styles or classes be changed in elements using JavaScript?
JavaScript can be used to easily modify classes and styles in an element by making use of the following syntax:
Modify styles: document.getElementById(“input”).style.fontSize = “10”; Modify class: document.getElementById(“button”).className = “classname”;
Next up on this top Web Development interview questions and answers blog, let us take a look at the advanced set of questions.
CTA
35. What are the types of popup boxes present in JavaScript?
There are three types of dialog boxes, which are used in JavaScript:
- Alert: Presents users with a message and an ‘Ok’ button
- Confirm: Gives the users a window with ‘Ok’ and ‘Cancel’ buttons
- Prompt: Shows the user input, alongside ‘Ok’ and ‘Cancel’ buttons
36. What is the difference between <window.onload> and <onDocumentReady>?
The <window.onload> event is not called until a page is completely loaded with the entire styling from CSS and images. The event does add a bit of delay when rendering a web page. With the <onDocumentReady> event, it will wait only till the DOM is initialized and will begin the event action. This ensures reduces any delays in actions.
37. How is type conversion handled in JavaScript?
JavaScript supports automatic type conversion. Since it is weakly typed, you can pass a function as an argument into another function easily.
This ensures that there are no errors or data type-associated warnings as values get converted to the required data type automatically.
39. How are comments used in JavaScript?
JavaScript supports two types of comment insertion in the code. Single-line comments and multi-line comments.
- Single-line comment: “//” is used for single-line comment insertion
Example:
//This is a single-line comment
- Multi-line comment: “/* */” is used to add multi-line comments
Example:
/* This is a multi-line comment*/
Coming to the next set of interview questions for web developers, here is a common question for JavaScript.
40. What are undefined and undeclared variables in JavaScript?
Variables that have been declared already but not initialized are known as undefined variables.
On the other hand, if a variable is being used in a program without being declared, then it is considered an undeclared variable.
Consider the following example:
var undefVar; alert(undefVar); // undefined variable alert(notDeclared); // accessing an undeclared variable
42. Why is <this> keyword used a lot in JavaScript?
The <this> keyword is used to access the current object present in a program. This object resides inside a method, and the keyword is used for referencing the corresponding variable or the object.
43. What is the use of the <defer> attribute in JavaScript?
The attribute is used as a boolean type attribute. It is used to delay the execution of the JavaScript code on a web page until the parser completely loads and initializes the page.
For example:
44. How can you prioritize SEO, maintainability, performance, and security in a web application?
This is a commonly asked question in a Web Development interview. Here, the interviewer is trying to assess your understanding of the working environment in the firm you’ve applied for.
If it is a large firm, then security will get higher priority over SEO. Whereas, if it is a publication firm, SEO gets the preference. A little groundwork about the company should help you answer this question.
The next web developer interview question we will look at is regarding jQuery. Let’s check it out.
45. What is the result if a jQuery Event Handler returns false?
If the jQuery Event Handler returns a boolean false value, it simply means that the event will not execute further and will halt the execution for the particular action it is associated with.
46. What is the use of the each() function in jQuery?
The each() function in jQuery is used to iterate over a set of elements. A function can be passed to each() method. This will result in the execution of each of the events for which the object has been called.
47. What is Pair Programming?
Pair programming is a scenario where you will be working closely with a colleague on the project, and this is done to help solve the problems at hand. If the development scenario is fast-paced, Agile development might not work efficiently. The interviewer asks this question to see whether you can work with other people easily and effectively.
48. What is the use of the $() function in jQuery?
The $() function is used as a wrapper to wrap objects into their jQuery counterparts. This is done to give users the ability to call any method that is defined for the jQuery object.
Note: Selectors can also be passed to the $() function, resulting in the output of a jQuery object that contains matched DOM elements.
49. What are the advantages of using a Content Delivery Network (CDN) in jQuery?
CDNs are widely used in jQuery as they offer an ample number of advantages for users.
- CDNs cause a significant reduction in the load for the server.
- They provide large amounts of savings in the bandwidth.
- jQuery frameworks load faster due to optimizations.
- CDNs have a caching ability that adds to quicker load times.
1. What is HTML?
HTML stands for HyperText Markup Language and it is the language of the internet. This standard text formatting language is used to create and display pages on the Internet. HTML documents include elements and tags that format it for proper display on pages.
2. What are HTML tags?
HTML tags are used for placing elements in the proper and appropriate format. The tags, < and >, set them apart from the HTML content. It is not always necessary to close these HTML tags. For example, in the case of images, the closing tags are not required as tag.
3. What are HTML attributes?
Attributes are properties that are added to an HTML tag. They change the way the tag behaves or is displayed. Attributes are added right after the name of the HTML tag, inside the brackets. Attributes can be added to opening or self-closing tags, but never in closing tags.
For example, the tag has an src attribute, which can add the source from which the image should be displayed.
4. What is a marquee in HTML?
Marquee in HTML is used to scroll text or images on a web page. It can scroll up, down, left, or right automatically. Marquee can be applied by using tags.
5. How do you separate a section of texts in HTML?
A section of texts in HTML can be separated with the help of the following tags:
- <br> – It is used to separate the line of text by breaking the current line and moving the flow of the text to a new line.
- <p> – It is used to write a paragraph of text.
- <blockquote> – It is used to define large quoted sections.
6. Define the list types in HTML?
Following are the list types in HTML:
- Ordered list – The ordered list displays elements in a numbered format with the help of the <ol> tag.
- Unordered list – The unordered list displays elements in a bulleted format with the help of the <ul> tag.
- Definition list – The definition list uses <dl>, <dt>, and <dd> tags for displaying elements in definition form.
7. What are void elements in HTML?
HTML elements that do not have closing tags or do not need to be closed are known as void elements. For example
,
8. What is the advantage of collapsing white space?
In HTML, a blank sequence of whitespace characters is treated as a single space character. The browser collapses the multiple spaces into a single space character thus aiding a developer to indent lines of text without the need to worry about multiple spaces. In this way, the readability and understandability of HTML codes is maintained.
9. What are HTML entities?
In HTML some characters like ‘<’, ‘>’, ‘/’, etc. are reserved. To use them in web pages, character entities or HTML entities need to be used. Below are a few mapping between the reserved character and its respective entity character to be used.
| Character | Entity Name | Entity Number |
| < | < | < |
| > | > | > |
| & | & | & |
| (non-breaking space) Eg. 10 PM | Eg. <p>10  PM</p> |   |
10. What is the ‘class’ attribute in HTML?
The ‘class’ attribute specifies the class name for an HTML element. Multiple HTML elements can have the same class value. It is primarily used to associate the styles on the stylesheet with the HTML elements.
11. What is the difference between the ‘id’ attribute and the ‘class’ attribute of HTML elements?
Multiple elements in HTML can have the same class value. The same is not true for an id attribute of an element.
12. Describe the HTML layout structure.
For the purpose of displaying the intended content and specific UI, each web page has to include different components. However, few things in the HTML layout structure come templated and are universally accepted practices. For example:
- <header>: It is used to include the starting information about the web page
- <footer>: A footer represents the final section of a web page
- <nav>: It involves the navigation menu of the HTML page
- <article>: It is a set of information
- <section>: This defines the basic structure of a page and is used inside the article block
- <aside>: It is used for the sidebar content of a web page
13. Compare HTML & XML
| Criteria | HTML | XML |
| Deployed for | Rendering things on screen | Describing what things are |
| Functioning area | Human to computer interaction | Computer to computer interaction |
| Can explain what data means | No | Yes |
14. What is $() in jQuery library?
The $() function is an alias of the jQuery() function, at first it looks weird and makes jQuery code cryptic, but once you get used to it, you will love its brevity. $() function is used to wrap any object into a jQuery object, which then allows you to call various method-defined jQuery objects. You can even pass a selector string to the $()function, and it will return a jQuery object containing an array of all matched DOM elements. I have seen this jQuery asked several times, despite it being quite basic. It is used to differentiate between developers who knows jQuery and those who do not.
Check out this video on HTML Interview Questions and Answers
15. What are the advantages of using jQuery?
- Easy to use and learn
- Easily expandable
- Cross-browser support (IE 6.0+, FF 1.5+, Safari 2.0+, Opera 9.0+)
- Easy to use for DOM manipulation and traversal
- Large pool of built-in methods
- AJAX capabilities
- Methods for changing or applying CSS, creating animations
- Event detection and handling
- Tons of plug-ins for all kinds of needs
16. Explain the difference between ID selector and class selector in jQuery.
If you have used CSS, then you might know the difference between ID and class selector. It’s the same with jQuery. ID selector uses ID e.g. #element1 to select element, while class selector uses CSS class to select elements. When you just need to select only one element, use ID selector, while if you want to select a group of elements, having the same CSS class then use a class selector. There is a good chance that the interviewer will ask you to write a code using ID and class selector. From a syntax perspective, as you can see, another difference between ID and class selector is that the former uses “#” and later uses the “.” character.
17. What is the difference between $(this) and this keyword in jQuery?
This could be a tricky question for many jQuery beginners, but it’s in fact the simplest one. $(this) returns a jQuery object, on which you can call several jQuery methods e.g. text() to retrieve text, val() to retrieve value, etc. While this represents the current element, it’s one of the JavaScript keywords to denote the current DOM element in a context. You can not call the jQuery method on this until it’s wrapped using the $() function i.e. $(this).
18. What is the main advantage of loading the jQuery library using CDN?
This is a slightly advanced jQuery question, and don’t expect that jQuery beginners can answer that. Well, apart from many advantages including reducing server bandwidth and faster download, one of the most important advantages is that if the browser has already downloaded the same jQuery version from the same CDN, then it won’t download it again. Nowadays, almost any public website uses jQuery for user interaction and animation, so there is a very good chance that browsers already have the jQuery library downloaded.

19. What is “Semantic HTML?”
Semantic HTML is a coding style where the tags embody what the text is meant to convey. Also known as semantic markup, this HTML introduces meaning to the web page rather than just presentation. For example, a <p> tag indicates that the enclosed text is a paragraph.
Tags for bold and italic are not examples of semantic HTML as they just represent formatting and provide no indication of meaning or structure.
20. What is a class? What is an ID?
A class is a style (i.e., a group of CSS attributes) that can be applied to one or more HTML elements. This means it can apply to instances of the same element or instances of different elements to which the same style can be attached. Classes are defined in CSS using a period followed by the class name. It is applied to an HTML element via the class attribute and the class name.
The following snippet shows a class defined and its application to an HTML DIV element.
.test {
font-family: Helvetica;
font-size: 20;
background: black;
}
test
Also, you could define a style for all elements with a defined class. This is demonstrated with the following code that selects all P elements with specified column class.
p.column {
font-color: black;
}
An ID selector is a name assigned to a specific style. It can be associated with one HTML element with the assigned ID. Within CSS, ID selectors are defined with the # character followed by the selector name.
The following snippet shows the CSS example1 defined followed by the use of an HTML element’s ID attribute, which pairs it with the CSS selector.
#example1 {
background: blue;
}
21. What is Grouping?
When more than one selector shares the same declaration, they may be grouped together via a comma-separated list; this allows you to reduce the size of the CSS (every bit and byte is important) and makes it more readable. The following snippet applies the same background to the first three heading elements.h1, h2, h3 {background: red;}
22. Why do we use alternative texts in images?
Image mapping can get confusing if it is hard to understand which hotspots correspond to a particular link. Alternative texts include a description of each link making it easier to understand the hotspot links.
23. How to create a new HTML element?
New HTML elements can be created in the following way:
<script> document.createElement﴾"myElement"﴿ </script>
or
<myElement>hello Intellipaat!</myElement>
24. What are the uses of a span tag? Explain with an example.
The span tag is used for styling purposes like:
- Adding color to text
- Highlighting any color text
- Adding background on text
Example:
<span style="color:#ffffff;">
In this page we use span.
</span>
25. Explain the key differences between localStorage and sessionStorage objects.
The key differences between localStorage and sessionStorage objects are:
- The localStorage object stores data indefinitely, while sessionStorage object stores them for only one session.
- In the case of a localStorage object, when the browser window is closed, the data will not be erased. However, in the case of sessionStorage objects, the data will get erased after the browser window is closed.
- The data that is stored in the sessionStorage is accessible only in the current browser window. The data that is stored in the localStorage can be accessed by multiple browser windows.
26. What is the hierarchy when it comes to style sheets?
If there are three different style definitions in a single selector, precedence is given to the definition that is closest to the actual tag. Inline style sheets take priority over embedded style sheets. Between embedded style sheets an external style sheets, embedded style takes precedence.
27. How do active links differ from normal links?
Normal and active links have blue as their default color. Certain browsers are capable of detecting an active link when the mouse cursor hovers over that link. The other browsers detect the active link when the link has the focus. An active link is in the action of opening the resource that is being pointed to.
The normal link contains a pointer to another resource. Those links don’t have a mouse cursor over it. A normal link becomes an active link when the user clicks on it.
28. What is the significance of and tag in HTML?
<head> contains the information about the document. It is always enclosed in the <html> tag. <head> contains the webpage metadata and tags like <style>, <link>, <meta>, <script>, etc. that are not displayed on the web page. In an HTML document. there can be only one <head> tag and it is one used before the <body> tag.
<body> defines the body of an HTML document and is always enclosed within the <html> tag. Any content that needs to be displayed on the web page, such as text, audio, images, video, contents, can be done using tags like <p>, <img>, <audio>, <heading>, <video>, <div>, etc. These tags have to be enclosed within the <body> tag. There can be only one <body> element in an HTML document and it is used after the <head> tag.
29. How can a table be displayed on an HTML webpage?
Data can be displayed in a tabular format with the help of the <table> tag. It can also be used to manage the layout of the web page. For example, the header section, the navigation bar, the content of the body, and the footer section.
The following HTML tags are used when building a table on an HTML webpage:
| Tag | Description |
| <table> | This tag defines the table. |
| <tr> | The <tr> tag is used to define a row in the table. |
| <th> | It is used for defining the header cell in a table. |
| <td> | The <td> tag defines a cell in a table. |
| <caption> | It defines the table caption. |
| <colgroup> | It specifies a group of one or multiple columns for the purpose of formatting. |
| <col> | This tag is used with <colgroup> for specifying column properties for each column. |
| <tbody> | <tbody> groups the content of the body in a table. |
| <thead> | It groups the header content in a table. |
| <tfoot> | <tfoot> groups the footer content in a table. |
30. How do you create links to different sections within the same HTML web page?
Links to different sections can be created within the same web page by using the <a> tag, along with the # symbol for referencing.
31. How can you create nested web pages in HTML?
When there are web pages within a webpage, these are called nested web pages. These nested web pages in HTML can be developed with the help of the built-in <iframe> tag. It defines an inline frame. For example:
<!DOCTYPE html> <html> <body> <h2>HTML Iframes example</h2> <p> specify the size of the iframe using the height and width attributes: </p> <iframe src="https://intellipaat.com/" height="500" width="700"></iframe> </body> </html>
32. How can you add buttons in HTML?
Buttons can be added to an HTML web page by using the built-in Button tag.
<!DOCTYPE html> <html> <body> <h2>Example of HTML Button Tag</h2> <button name="button" type="button">CLICK HERE</button> </body> </html>
33. What are the different types of headings in HTML?
There are six different types of headings in HTML. These are defined using the <h1> to <h6> tags. Each heading type has a different text size–<h1> being the largest and <h6> being the smallest. For example:
<!DOCTYPE html> <html> <body> <h1>Place Heading 1 here</h1> <h2>Place Heading 2 here</h2> <h3>Place Heading 3 here</h3> <h4>Place Heading 4 here</h4> <h5>Place Heading 5 here</h5> <h6>Place Heading 6 here</h6> </body> </html>

34. How do CSS precedence/cascading rules work? How does the !important directive affect the rules?
CSS style rules “cascade” in the sense that they follow an order of precedence. Global style rules apply first to HTML elements, and local style rules override them. For example, a style defined in a style element in a webpage overrides a style defined in an external style sheet. Similarly, an inline style that is defined in an HTML element in the page overrides any styles that are defined for that same element elsewhere. The !important rule is a way to make your CSS cascade but also have the rules you feel are most crucial always be applied. A rule that has the !important property will always be applied no matter where that rule appears in the CSS document. So if you wanted to make sure that a property always applied, you would add the !important property to the tag. So, to make the paragraph text always red, in the above example, you would write:p { color: #ff0000 !important; }p { color: #000000; }
35. What is microdata in HTML5?
Microdata are a group of name-value pairs that extract data for search engines and site crawlers. Each name-value pair is called a property and a group of them is called an item. Most search engines follow schema.org vocabulary for the extraction of microdata.
- itemid – A unique, global identifier of an item
- itemprop – Adds properties to an item
- itemref – Provides a list of element IDs with additional properties
- itemtype – Specifies the vocabulary’s URL that will be used to define itemprop
- itemscope – Defines the itemtype’s scope that is associated with it
36. Explain HTML5 Graphics.
There are two kinds of graphics that are supported by HTML5:
1. Canvas – It is like drawing on a blank webpage. Different graphic designs can be added on web pages. There are various available methods for drawing different geometrical shapes. Following is an example of how it is used.
<!DOCTYPE HTML> <html> <head> </head> <body> <canvas width="300" height="300" style="border:2px solid;"></canvas> </body> </html>
2. SVG – SVG or Scalable Vector Graphics follows the XML format and these are used for diagrams or icons. Following is an example of how it is used.
<!DOCTYPE html> <html> <body> <svg width="400" height="110"> <rect width="300" height="100" style="fill:#FFF;stroke-width:2;stroke:#000" /> </svg> </body> </html>
37. What are the server-sent events in HTML5?
Server-sent events are those events that are pushed from the web server to the browsers. These events can be used to continuously update DOM elements.
In the case of polling since every time an HTTP connection is established and torn down, there is a lot of overhead. In server-sent events, there the HTTP connection is long-lived, which is a big advantage over polling.
To use a server-sent event, <eventsource> is used. This element’s SRC attribute specifies the URL from which it sends a data stream that contains the events.
<eventsource src = "/cgi-bin/myfile.cgi" />
39. What is the use of A novalidate attribute for the form tag in HTML5?
The value of the A novalidate attribute is a boolean type. It shows whether the data being submitted by the form will be validated in advance or not. The forms can be submitted without validation by making the value false. This helps users to resume it later as well.
<form action = "" method = "get" novalidate> Name:<br><input type="name" name="sname"><br> Doubt:<br><input type="number" name="doubt"><br> <input type="submit" value="Submit"> </form>
40. What are the different ways of making an image responsive?
- Art Direction – The landscape image fully shown in the desktop layout can be zoomed in with the main subject in focus for a portrait layout by using <picture>.
For example:
<picture> <source media="(min-width: 650px)" srcset="img_flower.jpg"> <img src="img_marsh.jpg" style="width:auto;"> </picture>
For any other screen:
- Resolution Switching – Instead of zooming and cropping, the images can be scaled accordingly with the help of vector graphics. It can be set to serve different pixel density screens as well.
For example SVG:
<svg width="100" height="100"> <circle cx="50" cy="50" r="40" stroke="green" stroke-width="4" fill="yellow" /> </svg>
41.What is a manifest file in HTML5?
The manifest file lists down the resources that can be cached. This information is used by browsers making the web pages load faster than the first time. The manifest file contains three sections:
- CACHE Manifest – Files that are needed to be cached
- Network – Files that are never to be cached but always need a network connection
- Fallback – Fallback files if a page is inaccessible
CACHE MANIFEST
# 2012-06-16 v1.0.0 /style.css /logo.gif /main.js NETWORK: login.php FALLBACK: /html/ /offline.html <!DOCTYPE HTML> <html manifest="tutorial.appcache"> ... ... </html>
42. What is the geolocation API in HTML5?
The geolocation API in HTML5 shares a client’s physical location with websites. It provides a unique experience to users and locale-based content based on their location. The geolocation API works with a new property of the global navigator object. Most of the modern browsers support this.
var geolocation = navigator.geolocation;
43. What happens if there is no text between the tags? Is there any effect on the display of the HTML file?
If there is no text between tags, there is nothing to format so no formatting will be there. Some tags, like tags that don’t have a closing tag (for example, the <img> tag), do not need to have text between them.
44. How can JavaScript be added to an HTML webpage?
JavaScript makes HTML web pages user-friendly and more interactive. Based on the user input, it allows one to interact with particular page elements. There are three ways one can add JavaScript:
i) Inline: JavaScript can be added to HTML elements directly whenever a certain event occurs. The code can be added using the attributes of the HTML tags that support it.
ii) Script block: A script block can be defined anywhere on the HTML code. When the browser reaches that specific part of the document, the script block will get executed. This is the reason why they are typically added at the bottom of HTML documents.
iii) External JavaScript file: JavaScript code can be imported from a separate file. This maintains a clutter-free HTML code. It is especially useful when there is a large amount of scripting added to an HTML webpage.
45. How can CSS styling be added in HTML?
There are three ways to add CSS in HTML:
- Inline CSS: Inline CSS is used when there is less amount of styling required or where only a single element needs styling. Add the style attribute in the relevant tag to use inline styles.
- External Style Sheet: External style sheets are used when the style is applied to several elements or HTML pages. Each page must be linked to the style sheet with the <link> tag.
<head> <link rel="stylesheet" type="text/css" href="mystyle.css" /> </head>
- Internal Style Sheet: Internal style sheets are used when an HTML document has a unique style and multiple elements need to be styled to follow the format. This styles sheet is added in the head section of an HTML page with the <style> tag.
<head>
<style type="text/css">
hr {
color: sienna;
}
p {
margin-left: 20px;
}
body {
background-image: url("images/back40.gif");
}
</style>
</head>CSS CSS
1. What is CSS?
Cascading Style Sheet (CSS) is a style sheet language that is used to determine how the elements or content in a page will look or be displayed. It helps build a consistent look and feel for all web pages.
CSS allows the separation of the content from the presentation, thus providing more flexibility and control over the look of the website.
CSS3, the third version of the CSS standard, incorporates CSS2 standards with some improvements such as the inclusion of divisions of standards into different modules. It makes CSS3 easier to learn and understand.
2. What is an external style sheet? How would you link to it?
The external style sheet is the sheet that comprises style information and can be connected with one or more HTML documents. With the help of an external style sheet, the entire website can be formatted and styled just by editing one single file. The file is connected with HTML documents with the help of the LINK element, which resides inside the HEAD element.
3. What are the advantages and disadvantages of using external style sheets?
The advantages of using external style sheets are as follows:
- Styles of numerous documents can be organized from one single file.
- Classes can be made for use on numerous HTML element types in many forms of the site.
- In complex contexts, methods such as selector and grouping can be implemented to apply styles.
The disadvantages of using external style sheets are as follows:
- An extra download is necessary to import style information for each file.
- The execution of the file may be deferred till the external style sheet is loaded.
- While implementing style sheets, we need to test web pages with multiple browsers in order to check compatibility issues.
4. What are the advantages and disadvantages of embedded style sheets?
The advantages of embedded style sheets are as follows:
- In embedded style sheets, it is possible to generate classes for use on multiple tag types in a document.
- In embedded style sheets, in comparison to external style sheets, no extra download is compulsory to import the information.
The disadvantage of embedded style sheets are as follows:
- In embedded style sheets, controlling the styles for multiple files from one file is not possible.
5. What is a CSS selector?
A CSS selector is the portion of a CSS set that chooses the content that requires a specific style. A CSS selector is also referred to as a connection between the stylesheet and HTML files. A CSS selector permits you to choose and operate HTML elements. CSS selectors are used to select or find HTML elements created on their id, class, type, etc.
6. What is tweening?
Also known as in-betweening, tweening is the process of creating intermediary frames between two images to provide the appearance that the first image develops efficiently into the second image. It is a key process that is used in all types of animations. Refined animation software permits you to find particular objects in an image and describe how they will be able to move and change throughout the tweening process.
7. What is the box model in CSS? Which CSS properties are a part of it?
A rectangle box is wrapped around every HTML element. The CSS box model is used to determine the height and width of the rectangular box. If it is not mentioned, then default values and content are added inside. The CSS box also includes borders, margins, and padding.
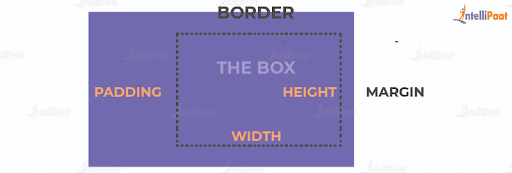
- Content: It refers to the actual content of the box where the text or image is placed.
- Padding: It is the area surrounding the content, and it is the space between the border and the content.
- Border: It is the area that surrounds the padding.
- Margin: It refers to the area that surrounds the border.
8. How can you include CSS in a web page?
There are different ways by which you can include a CSS in a web page:
- External Style Sheet: An external file is linked to the HTML document using the link tag.
<link rel="stylesheet" type="text/css" href="mystyles.css" />
- Embed CSS with a Style Tag: Another way to include CSS in a web page is by having a set of CSS styles included within the HTML page.
<style type="text/css"> /*Add style rules here*/ </style>
The CSS rules have to be added between the opening and closing style tags. The CSS is written exactly like the standalone stylesheet files.
- Inline Styles to HTML Elements: Style can be added directly to the HTML element with the help of a style tag.
<h2 style="color:red;background:black">Inline Style</h2> - Import a Style-sheet File: Another way to add CSS is by using the @import rule. Here, an external file is imported to another CSS file. This is for adding a new CSS file within the CSS itself.
@import "path/to/style.css";
9. What are the different types of selectors in CSS?
A CSS selector in a CSS rule set helps select the content that needs to be styled. The different types of selectors are listed below:
- Universal Selector: The universal selector selects all elements on a page. The provided styles will get applied to all the elements on the page.
* { color: "green"; font-size: 20px; line-height: 25px; }
- Element Type Selector: The element type selector selects one or more HTML elements of the same name. In the example below, the provided styles will be applied to all the ul elements on the page.
ul { line-style: none; border: solid 1px #ccc; }
- ID Selector: The ID selector is used for selecting any HTML element that has an ID attribute same as the selector. In the below example, the assigned styles will get applied to all the elements having the ID container.
#container { width: 960px; margin: 0 auto; } <div id="container"></div>
- Class Selector: The class selector choses all the page elements with class attributes that are set to the same value as the class. The styles get applied to all the elements having the same ID on the page.
.box { padding: 10px; margin: 10px; width: 240px; } <div class="box"></div>
- Descendant Combinator: The descendant selector or, more accurately, the descendant combinator lets you combine two or more selectors and be more specific in the selection method.
#container .box { float: left; padding-bottom: 15px; } <div id="container"> <div class="box"></div> <div class="box-2"></div> </div> <div class=”box”></div>
In the above example, the declaration block applies to all elements having a class, “box”, that is inside an element with the ID, “container”. It is worth noting that the .box element does not have to be an immediate child; there can be another element wrapping the .box, and the styles will still apply.
- Child Combinator: The child combinator is similar to the descendant combinator, except it only targets immediate child elements.
#container> .box { float: left; padding-bottom: 15px; } <div id="container"> <div class="box"></div> <div> <div class="box"></div> </div> </div>
The selector will match all elements that have a class, “box”, and are immediate children of the element, “container”.
- General Sibling Combinator: The general sibling combinator matches elements based on sibling relationships. The selected elements are adjacent to each other in HTML.
h2 ~ p { margin-bottom: 20px; } <h2>Title</h2> <p>Paragraph example.</p> <p>Paragraph example.</p> <p>Paragraph example.</p> <div class=”box”> <p>Paragraph example.</p> </div>
In the above example, all paragraph elements, (<p>), will be styled with the specified rules, but only if they are siblings of <h2> elements. Even if there are other elements in between <h2> and <p>, the styles will still apply.
- Adjacent Sibling Combinator: The adjacent sibling combinator is almost the same as the general sibling selector but the targeted element must be an immediate sibling, not just a general sibling. The adjacent sibling combinator uses the plus symbol, (+).
p + p { text-indent: 1.Sem; margin-bottom: 0; } <h2>Title</h2> <p>Paragraph example.</p> <p>Paragraph example.</p> <p>Paragraph example.</p> <div class=”box”> <p>Paragraph example.</p> <p>Paragraph example.</p> </div>
In the above example, the specified styles will apply only to those paragraph elements that immediately follow other paragraph elements. This means that the first paragraph element on a page will not receive these styles.
If there are other elements appearing between two paragraphs, the styles will not apply to the second paragraph.
- Attribute Selector: The attribute selector targets elements based on the presence and/or value of HTML attributes. It is declared using square brackets.
input [type=”text”] { background-color: #444; width: 200px; } <input type="text">
10. What is a CSS preprocessor? What are SASS, LESS, and Stylus? Why do people use them?
A CSS preprocessor allows us to generate CSS from the preprocessor’s own unique syntax. It extends the basic functionality of default vanilla CSS through its own scripting language. With a CSS preprocessor, it is possible to use complex logical syntax such as variables, mixins, functions, code nesting, inheritance, etc.
SASS: Syntactically awesome style sheets (SASS) is a CSS preprocessor. It reduces the repetition of CSS, thus saving time. SASS can be written in two different syntaxes. The original syntax, called the indented syntax, uses indentation to separate code blocks and newline characters to separate rules.
The newer syntax, Sassy CSS (SCSS), uses block formatting, like CSS, and braces to denote code blocks and semicolons to separate rules within a block. The indented syntax and SCSS files have the extensions .sass and .scss respectively.
LESS: Learner style sheets, or LESS, are easy to add to any JavaScript project with the help of npm or less.js file. It uses the extension .less. LESS syntax is similar to SCSS with some exceptions. It uses @ to define the variables.
Stylus: Stylus is quite flexible when it comes to writing syntax. It supports native CSS and allows omission of colons, semicolons, and brackets. @ or $ does not need to be used for defining variables.
These CSS processors are used because they help build inventive features to CSS by using variables, mixins, nesting, and extending.
11. What is the difference between reset CSS and normalize CSS?
Reset CSS attempts to remove all built-in browser styling, while normalize CSS aims for consistency in built-in browser styling across browsers. Normalize CSS also fixes bugs for common browser dependencies.
12. What is the difference among inline, inline-block, and block elements?
Block Element: Block elements always start on a new line and occupy an entire row or width. Examples of block elements are <div> and <p>.
Inline Elements: Inline elements do not start on a new line; they appear on the same line as the content and tags beside them. Some examples of inline elements are <a>, <strong>, <span>, and <img>.
Inline-block Elements: Inline-block elements are similar to inline elements, but they can have padding, margins, and set height and width values.
13. What are pseudo-elements and pseudo-classes?
Pseudo-elements help to create items that do not normally exist in the document tree. The examples of pseudo-elements are:
- ::before
- ::after
- ::selection
- ::first-letter
- ::first-line
Pseudo-classes select regular elements under specific conditions such as when a user is hovering over a link. The examples of pseudo-classes are:
- :hover
- :active
- :link
- :visited
- :focus
14. What is a responsive web design?
A responsive web design is about design and development that responds to the user activities and the components involved such as screen size, platform, and orientation. It comprises a mix of flexible grids, layouts, images, and intellectual use of CSS media queries.
15. What are the differences between adaptive design and responsive design?
| Adaptive Design | Responsive Design |
| It focuses on multiple fixed layout sizes in website development. | It focuses on showing content based on available browser space. |
| In this kind of website design, first, the available space is detected and then the layout, with most appropriate size, is picked and used to display the content. Resized browser window has no effect on the design. | In this kind of website design, when the browser window is resized, the content of the website is dynamically and optimally rearranged to accommodate the window. |
| It uses six standard screen widths, 320 px, 480 px, 760 px, 960 px, 1200 px, and 1600 px. | Depending on the target device’s properties, it uses CSS media queries to change styles for adapting to different screens. |
| It takes a lot of time and effort because the options and realities of the end users need to be examined first and then the best possible adaptive solutions are designed. | Building and designing fluid websites that can accommodate content depending on the screen size does not take much work. |
| It gives a lot of control over the design for specific screens. | It does not allow much control over the design. |
16. What is the difference between physical and logical tags?
Logical tags mainly focus on the content and are older as compared to the physical tags. Logical tags are hardly used in terms of presentation. In terms of aesthetics, logical tags do not serve any purpose. However, physical tags find their application in presentation.
17. What is the use of CSS image sprites?
It is a group of images placed into one image. A web page with multiple images can take a lot of time to load and uses multiple server requests to project the same. With the help of image sprites, we can decrease the number of requests to the server and save time and bandwidth as well.
18. What is the syntax to link an external style sheet?
An external style sheet comprises style description that can be linked with the HTML document externally. An external style sheet is one of the best and most organized ways to keep the style separate from the structure.
The syntax for linking an external style sheet is as follows:
<HTML> <HEAD> <LINK REL=STYLESHEET HREF="Test.css" TYPE="text/css"> </HEAD> </HTML>
19. How can embedded style be linked with HTML documents?
Embedded style can be implemented within HTML code. It is written using the <Style> tag and used under the <Head> structure.
Its syntax is as follows:
<HEAD> <STYLE TYPE=”text/css”> style {text-indent: 15pt;} style1{text-color: #060000;} </STYLE> </HEAD>
20. Why is the imported function an easy way to insert a file?
An imported style sheet permits us to import external files or combine one style sheet with another. Many files can be created, and different style sheets have different functions. The import function gives the provision to combine many elements or functionalities into one. The syntax to import any file is @import notation, which is used inside the <Style> tag. There is a one rule that implies that the last imported sheet will override the previous ones.
The syntax is shown by coding as:
<Link Rel=Stylesheet Href=”Main.Css” Type=”Text/Css”> <STYLETYPE=”text=css”> <!– @import url(http://www.xyz.css); …. your code –> </STYLE>
The <!– –> tag is used as a comment for browsers that do not support CSS.
21. What are the advantages of using CSS?
The main advantages of using CSS are:
- Separation of Content from Presentation: CSS enables presentation of the same content in multiple formats for mobile, desktop, or laptop.
- Bandwidth: When CSS is used effectively, the browser cache can store the style sheets and these can be used on multiple pages without the need to redownload.
- Easy to Maintain: By making small changes, CSS can be used to completely change the look and feel of a web page. For a global change, we simply have to change the style, and all elements in all web pages will be automatically updated.
22. How are the CSS selectors matched against the elements by the browser?
The order of matching selectors is from right to left of the selector expression. Based on the key selectors, DOM elements are filtered by browsers and are then traversed up to the parent elements to determine the matches. The speed of deciding the elements is based on the length of the chain of selectors.
23. How is border-box different from content-box?
The border-box property contains the content, border, and padding in height and width properties. If you look at the example below, the box-sizing for the div element is set as border-box. The height and width considered for the div content will also include the padding and border:
div{ width:300px; height:200px; padding:15px; border: 5px solid grey; margin:30px; -moz-box-sizing:border-box; -webkit-box-sizing:border-box; box-sizing:border-box; }
The actual height of the div content in this case is:
actual height = height - padding on top and bottom - border on top and bottom = 200 - (15*2) - (5*2) = 160 px The actual width of the div content in this case is: actual width = width - padding on right and left - border on right and left = 300 - (15*2) - (5*2) = 260 px
Let us take a look at the border-box model for the above example:
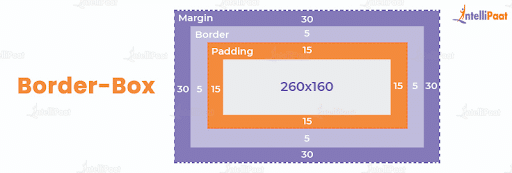
Content-box, on the other hand, is the default value box-sizing property. Height and the width properties do not include border and padding and only have content. For example:
div{ width:300px; height:200px; padding:15px; border: 5px solid grey; margin:30px; -moz-box-sizing:content-box; -webkit-box-sizing:content-box; box-sizing:content-box; }
Here, content-box is the box-sizing for the div element. The height and width for the div content do not include padding and border. The full height and width parameters are specified for the content as shown below:

24. Explain RGB stream
RGB represents the colors in CSS. The RGB streams are namely red, green, and blue. The intensity of the colors can be set from 0 to 255. It enables CSS to have a spectrum of visible colors.
25. Define z-index
Z-index helps specify the stack order of elements that overlap each other. While the default value of z-index is zero, it can take both positive and negative values. An element with a greater stack order is always above the element with a lower stack order.
Z-index can assume the following values:
- auto: It sets the stack order equal to its parents.
- number: It sets the stack order of the element. Negative values are allowed.
- initial: It sets this property to its default value.
- inherit: It inherits this property from its parent element.
26. When should translate () be used instead of absolute positioning?
Translate is a CSS transform value. Changing the opacity or transform does not trigger the browser reflow or repaint. Transform requires the browser to create a GPU layer for elements. However, CPU usage changes absolute positioning properties.
translate() involves reduced paint times and is more efficient. Unlike when changing absolute positioning, the element occupies original space when translate () is used.
27. Name the different ways to position some aspects in CSS
The positioning method type is determined by the positioning property. The five different position values are:
- fixed
- static
- absolute
- sticky
- relative
The elements are positioned with the help of top, left, right, and bottom properties. These properties need to be set first, and they work depending on position value.
29. How can a web page be optimized for prints?
A website typically contains a header, footer, sidebar, navbar, and main content area. The content sections of the website need to be identified and controlled. By doing so, most of the work is done.
The integrity of the website should not be changed. It is recommended to use page breaks, create a style sheet for print, size the page for print, and avoid unnecessary HTML tables.
30. What is the property that is used to control image scroll?
The background-attachment property is used to set whether the background image remains fixed or is scrollable with the rest of the page. Here is an example for a fixed background-image:
body { background-image: url(‘url_of_image’); background-repeat: no-repeat; background-attachment: fixed; }
Jquey Jquey
1. Compare Jquery & AngularJS
| Criteria | JQuery | AngularJS |
| Availability of RESTful API | No | Yes |
| Support for MVC | No | Yes |
| Two-way data binding | No | Yes |
2. What is $() in jQuery library?
The $() function is an alias of jQuery() function, at first it looks weird and makes jQuery code cryptic, but once you get used to it, you will love it’s brevity. $() function is used to wrap any object into jQuery object, which then allows you to call various method defined jQuery object. You can even pass a selector string to $()function, and it will return a jQuery object containing an array of all matched DOM elements. I have seen this jQuery asked several times, despite it’s quite basic, it is used to differentiate between the developer who knows jQuery or not.
3. What are the advantage of using jQuery?
- Easy to use and learn.
- Easily expandable.
- Cross-browser support (IE 6.0+, FF 1.5+, Safari 2.0+, Opera 9.0+)
- Easy to use for DOM manipulation and traversal.
- Large pool of built in methods.
- AJAX Capabilities.
- Methods for changing or applying CSS, creating animations.
- Event detection and handling.
- Tons of plug-ins for all kind of needs.
4. Difference between ID selector and class selector in jQuery?
If you have used CSS, then you might know the difference between ID and class selector, It’s same with jQuery. ID selector uses ID e.g. #element1 to select element, while class selector uses CSS class to select elements. When you just need to select only one element, use ID selector, while if you want to select a group of element, having same CSS class than use class selector. There is good chance that, Interview will ask you to write code using ID and class selector. From syntax perspective, as you can see, another difference between ID and class selector is that former uses “#” and later uses “.” character. More detailed analysis and discussion, see answer.
5. Difference between $(this) and this keyword in jQuery?
Could be a tricky questions for many jQuery beginners, but indeed it’s simplest one. $(this) returns a jQuery object, on which you can call several jQuery methods e.g. text() to retrieve text, val() to retrieve value etc, while this represent current element, and it’s one of the JavaScript keyword to denote current DOM element in a context. You can not call jQuery method on this, until it’s wrapped using $() function i.e. $(this).
6. What is main advantage of loading jQuery library using CDN?
This is slightly advanced jQuery question, and don’t expect that jQuery beginners can answer that. Well, apart from many advantages including reducing server bandwidth and faster download, one of the most important is that, if browser has already downloaded same jQuery version from same CDN, than it won’t download it again. Since now days, almost many public websites use jQuery for user interaction and animation, there is very good chance that browser already have jQuery library downloaded. Curious reader, please see the answer for in depth analysis.
7. How do CSS precedence/cascading rules work? How does the !important directive affect the rules?
CSS style rules “cascade” in the sense that they follow an order of precedence. Global style rules apply first to HTML elements, and local style rules override them. For example, a style defined in a style element in a webpage overrides a style defined in an external style sheet. Similarly, an inline style that is defined in an HTML element in the page overrides any styles that are defined for that same element elsewhere.The !important rule is a way to make your CSS cascade but also have the rules you feel are most crucial always be applied. A rule that has the !important property will always be applied no matter where that rule appears in the CSS document. So if you wanted to make sure that a property always applied, you would add the !important property to the tag. So, to make the paragraph text always red, in the above example, you would write:
p { color: #ff0000 !important; }
p { color: #000000; }
8. What is a class? What is an ID?
A class is a style (i.e., a group of CSS attributes) that can be applied to one or more HTML elements. This means it can apply to instances of the same element or instances of different elements to which the same style can be attached. Classes are defined in CSS using a period followed by the class name. It is applied to an HTML element via the class attribute and the class name.The following snippet shows a class defined, and then it being applied to an HTML DIV element..test {font-family: Helvetica; font-size: 20; background: black;}<div class =”test”><p>test</p></div>Also, you could define a style for all elements with a defined class. This is demonstrated with the following code that selects all P elements with the column class specified.
p.column {font-color: black;}
An ID selector is a name assigned to a specific style. In turn, it can be associated with one HTML element with the assigned ID. Within CSS, ID selectors are defined with the # character followed by the selector name.
The following snippet shows the CSS example1 defined followed by the use of an HTML element’s ID attribute, which pairs it with the CSS selector.
#example1: {background: blue;}
<div id=”example1″></div>
10. What is HTML?
HTML is short for HyperText Markup Language and is the language of the World Wide Web. It is the standard text formatting language used for creating and displaying pages on the Web. HTML documents are made up of two things: the content and the tags that formats it for proper display on pages.
11. What is “Semantic HTML?”
Semantic HTML is a coding style where the tags embody what the text is meant to convey. In Semantic HTML, tags like <b></b> for bold, and <i></i> for italic should not be used, reason being they just represent formatting, and provide no indication of meaning or structure. The semantically correct thing to do is use <strong></strong> and <em></em>. These tags will have the same bold and italic effects while demonstrating meaning and structure (emphasis in this case).
ANGULAR ANGULAR
1. What is Angular?
Angular is an open-source web application development framework created by Google. It is used to build frontend, single-page applications that run on JavaScript. It is a full-fledged framework, i.e., it takes care of many aspects of frontend web applications such as HTTP requests, routing, layout, forms, reactivity, validation, etc.
2. What are the technologies used in Angular?
Angular is a modern frontend JavaScript framework developed by Google. Angular itself makes use of several technologies for several reasons to accomplish certain tasks easily as well as to allow developers to have a better experience while developing applications with it. Angular uses TypeScript, which is a superscript of JavaScript. So, any valid JavaScript is a valid TypeScript. However, TypeScript allows us to write JavaScript as a strongly typed language, and we can define our own types as well, which makes catching bugs much easier. It also uses RxJS, which allows developers to better deal with asynchronous operations.
3. Why were client-side frameworks like Angular introduced?
Before JavaScript-based client-side frameworks, the way dynamic websites worked was by taking a template that is nothing but HTML code with spaces left empty for feeding data and content into those templates. This data was usually fetched from a database. After combining the template and data, we would serve the generated HTML content back to the user. As you can see, it was a bit complicated, and in some cases, it took a lot of processing.
To overcome these issues, people came up with another approach in which they send the necessary data to render a page from their web servers to the web browsers and let JavaScript combine this data with a predefined template. Now, even mobile phones are powerful enough to do this kind of processing, the servers can now just send the data to a client over the internet in a recognizable format, i.e., JSON, XML, etc. This drastically reduces the processing done on the servers and improves performance.
4. What is the difference between Angular and AngularJS?
Following are some of the major and significant differences between Angular and AngularJS:
| Features | Angular | AngularJS |
| Architecture | It makes use of directives and components | It supports the Model-View-Controller or MVC model |
| Language | It uses TypeScript language, a superset of JavaScript that is typed statistically | It uses JavaScript, a dynamically typed language |
| Expression Syntax | Angular uses () to bind an event while [] to bind a property | It requires professionals to use the correct ng directive to bind a property or an event |
| Mobile Support | Angular offers mobile support | Unlike Angular, AngularJS does not offer mobile support |
| Routing | It uses @RouteConfig{(…)} | It uses $routeprovider.when() |
| Dependency Injection | It supports hierarchical dependency injection, along with a unidirectional tree-based change direction | It does not support dependency injection |
| Structure | Its simplified structure makes it easy for professionals to develop and maintain large applications easily | It is comparatively less manageable |
5. What are some advantages of using Angular?
Using Angular has several advantages, which are listed below:
- Angular is built using TypeScript, which allows developers to write strongly typed code that will get transpiled into JavaScript. The benefits of strongly typed code are that it is easy to read, maintainable, and less prone to errors. Also, it provides better tooling with type hints and code completion.
- Angular allows us to separate our code into modules, which can be used to wrap functionalities related to a specific task such as HTTP communication, data validation, routing, etc.
- Angular has a large ecosystem of tools, libraries, frameworks, plugins, etc. that make the whole development experience much faster and more enjoyable. These tools and libraries include Angular CLI, RxJS, NgRx, etc.
6. What do you mean by data binding?
Data binding is among the most important and powerful features that help in establishing communication between DOM and the component. It makes the defining process of interactive applications simple as you no longer need to panic about data pushing or pulling between the component and the template.
Listed below are the four types of data binding in Angular:
- Event binding
- Property binding
- String interpolation
- Two-way data binding
7. What are some disadvantages of using Angular?
Although Angular provides quite a lot of benefits, there are some disadvantages of using it as well. They are as follows:
- Getting good SEO results on an Angular application can be a bit difficult and may need a bit of configuration.
- Angular has a lot of features packed into it, so getting to know each of them and learning how to use them effectively together can be a little difficult.
- Angular can add quite a lot of weight to your JavaScript bundle, so using it for smaller projects can be very inefficient and may significantly increase the load size.
8. What do you mean by string interpolation?
String interpolation in Angular, also known as the mustache syntax, only allows one-way data binding. It is a special syntax that makes use of double curly braces {{}} so that it can display the component data. Inside the braces are the JavaScript expressions that Angular needs to execute to retrieve the result, which can further be inserted into the HTML code. Moreover, as part of the digest cycle, these expressions are regularly updated and stored.
9. What are the differences between Angular decorator and annotation?
In Angular, decorators are design patterns that help in the modification or decoration of the respective classes without making changes in the actual source code.
Annotations, on the other hand, are used in Angular to build an annotation array. They use the Reflective Metadata library and are a metadata set of the given class.
10. What is an AOT compilation in Angular?
The AOT (ahead-of-time) compiler in Angular converts Angular HTML and TypeScript code into JavaScript code during the build phase, which makes the rendering process much faster. This compilation process is needed since Angular uses TypeScript and HTML code. The compiler converts the code into JavaScript, which can then be effectively used by the browser that runs our application.
11. What are the advantages of AOT?
AOT compilation has several advantages as mentioned below:
- Fast rendering: Since, after compilation, the browser would download a pre-compiled version of our application, it can render the application immediately without compiling the app.
- Less asynchronous requests: It takes external HTML templates and CSS style sheets and inlines them within the application JavaScript, which reduces the number of separate Ajax requests.
- Smaller download size: The compiler will minify the code for us so that the download size is less.
- Template error detection: During the compilation phase, any issues in the templates will be detected and reported by the compiler so that they can be corrected before production.
12. What are the components in Angular?
Components are the basic building block of the user interface in Angular. A component consists of HTML, CSS, and JavaScript for a specific portion of a user interface. We can think of these as a custom HTML element that only Angular can understand. These components are isolated, i.e., styles and code from one component do not affect other components as they get namespaced by the compiler. These components are then pieced together by the Angular framework to build the user interface for the browser to render.
13. What are modules in Angular?
A module is a logical boundary of our application. It is used to encapsulate code dealing with a specific aspect of the application, such as routing, HTTP, validation, etc. The main reason why modules are used is to enhance application composability. For example, if we wish to implement validation logic using different libraries, then for the one we have already implemented, we can create a new validation module and replace the current one with the new one, and our application would work just the same. In Angular, we create a module using the NgModule decorator.
14. What is DOM?
The full form of DOM is Document Object Model, and it is responsible for representing the content of a web page and changes in the architecture of an application. Here, all the objects are organized in the form of a tree, and the document can easily be modified, manipulated, and accessed only with the help of APIs.
15. What are services in Angular?
A service in Angular is a term that covers broad categories of functionalities. A service is any value, function, or feature that an app needs. A service is typically used to accomplish a very narrow purpose such as HTTP communication, sending data to a cloud service, decoding some text, validating data, etc. A service does one thing and does it well. It is different from a component as it is not concerned with HTML or any other kind of presentation logic. Normally, a component uses multiple services to accomplish multiple tasks.
16. What is the difference between jQuery and Angular?
The main difference between jQuery and Angular is that jQuery is a JS library, whereas Angular is a JS frontend framework. Some of the other differences between the two are mentioned below:
- Unlike jQuery, Angular offers two-way data binding
- Unlike Angular, jQuery does not offer support for the RESTful API
- Angular supports deep linking routing, while jQuery does not
- Form validation is available in Angular but not in jQuery
Although they have their differences, Angular and jQuery also have their set of similarities, like both jQuery and Angular expressions consist of variables, operators, and literals.
17. What are lifecycle hooks in Angular?
When building an Angular app, there will be times when we need to execute some code at some specific event—such as when a component is initialized or displayed on the screen or when the component is being removed from the screen. This is what lifecycle hooks are used for. For example, if we have some event listener attached to an HTML element in a component, such as a button click or form submission, we can remove that event listener before removing the component from the screen, just like we can fetch some data and display it on the screen in a component after the component is loaded on the screen. To use a lifecycle hook, we can override some methods on a component, such as ngOnInit or ngAfterViewInit. These methods, if available on a component, will be called by Angular automatically. This is why these are called lifecycle hooks.
18. What are templates?
Angular templates are written using HTML that includes attributes and elements that are specific to Angular. The templates are further combined with the data from the controller and the model, which can be rendered to offer the user a dynamic view.
19. What is a two-way data binding?
Two-way data binding is done in Angular to ensure that the data model is automatically synchronized in the view. For example, when a user updates some data in a model and that model is being displayed in multiple places in a component, that update should be reflected in all the places.
Two-way data binding has been supported in Angular for a long time. Although, it is something that should be used with careful consideration as it could lead to poor application performance or performance degradation as time goes on. It is called two-way data binding because we can change some data that is in the component model from the view that is HTML, and that change can also propagate to all other places in the view where it is displayed.
20. What are pipes in Angular?
When we are trying to output some dynamic data in our templates, we may sometimes need to manipulate or transform the data before it is put into our templates. Though there are several ways of doing that, in Angular, using pipes is the most preferred way. A pipe is just a simple function, which we can use with expressions in our templates.
Pipes are extremely useful as we can use them throughout our application after declaring them just once and registering them with the Angular framework. Some of the most common built-in pipes in Angular are UpperCasePipe, LowerCasePipe, CurrencyPipe, etc.
21. What are observables in Angular?
An observable is a declarative way using which we can perform asynchronous tasks. Observables can be thought of as streams of data flowing from a publisher to a subscriber. They are similar to promises as they both deal with handling asynchronous requests. However, observables are considered to be a better alternative to promises as the former comes with a lot of operators that allow developers to better deal with asynchronous requests, especially if there is more than one request at a time.
Observables are preferred by many developers as they allow them to perform multiple operations such as combining two observables, mapping an observable into another observable, and even piping multiple operations through an observable to manipulate its data.
22. How are observables different from promises?
Although both promises and observables are used to handle asynchronous requests in JavaScript, they work in very different ways. Promises can only handle a single event at a time, while observables can handle a sequence of asynchronous events over a period of time. Observables also provide us with a wide variety of operators that allow us to transform data flowing through these observables with ease.
A promise is just a way to wrap asynchronous operations so that they can be easily used, while an observable is a way to turn asynchronous operations into a stream of data that flows from a publisher to a subscriber through a well-defined path with multiple operations transforming the data along the way.
23. What does Angular Material mean?
Angular Material is a UI component library that allows professionals to develop consistent, attractive, and completely functional websites, web pages, and web applications. It becomes capable of doing so by following modern principles of web designing, such as graceful degradation and browser probability.
24. What is RxJS?
RxJS is a library, and the term stands for Reactive Extensions for JavaScript. It is used so that we can use observables in our JavaScript project, which enables us to perform reactive programming. RxJS is used in many popular frameworks such as Angular because it allows us to compose our asynchronous operations or callback-based code into a series of operations performed on a stream of data that emits values from a publisher to a subscriber. Other languages such as Java, Python, etc. also have libraries that allow them to write reactive code using observables.
25. What is bootstrapping?
Angular bootstrapping, in simple words, allows professionals to initialize or start the Angular application. Angular supports both manual and automatic bootstrapping. Let’s briefly understand the two.
- Manual bootstrapping: It gives more control to professionals with regards to how and when they need to initialize the Angular app. It is extremely useful in places where professionals wish to perform other tasks and operations before the Angular compiles the page.
- Automatic bootstrapping: Automatic bootstrapping can be used to add the ng-app directive to the application’s root, often on the tag if professionals need Angular to automatically bootstrap the application. Angular loads the associated module once it finds the ng-app directive and, further, compiles the DOM.
26. What do you mean by dependency injection?
Dependency injection (DI) in Angular is a software design pattern in which the objects can be passed in the form of dependencies instead of hard-coding them in the respective components. This concept is extremely handy when it comes to separating the object logic creation from its consumption.
The function ‘config’ uses DI that needs to be configured so that the module can be loaded to retrieve the application elements. Besides, this feature allows professionals to change dependencies based on necessities.
27. What are Angular building blocks?
The following building blocks play a crucial role in Angular:
- Components: A component can control numerous views wherein each of the views is a particular part of the screen. All Angular applications have a minimum of one component called the root component. This component is bootstrapped in the root module, the main module. All the components include the logic of the application that is defined in a class, while the main role of the class is to interact with the view using an API of functions and properties.
- Data binding: Data binding is the process in which the various sections of a template interact with the component. The binding markup needs to be added to the HTML template so that Angular can understand how it can connect with the component and template.
- Dependency injection: It uses DI so that it can offer the necessary dependencies, mainly services, to the new components. The constructor parameters of a component inform Angular regarding the numerous services needed by the component, and DI provides a solution that gives the necessary dependencies to the new class instances.
- Directives: Angular templates are of dynamic nature, and directives help Angular understand how it can transform the DOM while manifesting the template.
- Metadata: Classes have metadata attached to them with the help of decorators so that Angular will have an idea of processing the class.
- Modules: Module or NgModule is a block of code organized using the necessary capabilities set, having one specific workflow. All Angular applications have at least one module, the root module, and most of the applications have numerous modules.
- Routing: Angular router helps interpret the URL of a browser to get a client-generated experience and view. This router is bound to page links so that Angular can go to the application view as soon as the user clicks on it.
- Services: Service is a vast category that ranges from functions and values to features that play a significant role in Angular applications.
- Template: The view of each component is linked with a template, and an Angular template is a type of HTML tag that allows Angular to get an idea of how it needs to render the component.
28. Explain the MVVM architecture.
The MVVM architecture plays a significant role in eliminating tight coupling between the components. This architecture includes the following three parts:
- Model: The model represents the business logic and data of a particular application. In other words, it consists of an entity structure. The model has the business logic, including model classes, remote and local data sources, and the repository.
- View: View is the application’s visual layer that comprises the UI code. The view sends the action of the user to the ViewModel. However, it does not receive the response directly. The view must subscribe to the observables that are exposed to it by the ViewModel to receive a response.
- ViewModel: ViewModel is the application’s abstract layer that connects the View and the Model and acts as a bridge between the two. It does not know which View needs to be made use of since it does not have any direct access to the View. The two are connected using data binding, and the ViewModel records all the changes that are made to the View and makes the necessary changes to the Model.
29. Describe Angular authentication and authorization.
The login details of a user are given to an authenticate API available on the server. Once the credentials are validated by the server, it returns a JSON web token (JWT), which includes attributes and the data of the current user. Further, the user is easily identified using JWT, and this process is known as authentication.
After logging in, users have various types and levels of access—some can access everything, while others may have restrictions from some resources. Authorization determines the access level of these users.
30. What is the digest cycle process in Angular?
The digest cycle in Angular is the process in which the watchlist is monitored to track changes in the watch variable value. In each digest cycle, there is a comparison between the present and the previous versions of the scope model values.
31. What are the distinct types of Angular filters?
Filters are a part of Angular that helps in formatting the expression value to show it to the user. They can be added to services, directives, templates, or controllers. You also have the option to create personalized filters as per requirements. These filters allow you to organize the data easily such that only the data that meets the respective criteria are displayed. Filters are placed after the pipe symbol ( | ) while used in expressions.
Various types of filters in Angular are mentioned below:
- currency: It converts numbers to the currency format
- filter: It selects a subset containing items from the given array
- date: It converts a date into a necessary format
- lowercase: It converts the given string into lowercase
- uppercase: It converts the given string into uppercase
- orderBy: It arranges an array by the given expression
- JSON: It formats any object into a JSON string
- number: It converts a number value into a string
- limitTo: It restricts the limit of a given string or array to a particular number of elements or strings
32. How can one create a service in Angular?
Service in Angular is an object that can be substituted. It is wired and combined with the help of dependency injection. Services are developed by getting registered in a module that they need to be executed in. The three methods of creating a service in Angular are as follows:
- Service
- Factory
- Provider
33. What does subscribing mean in RxJS?
In RxJS, when using observables, we need to subscribe to an observable to use the data that flows through that observable. This data is generated from a publisher and is consumed by a subscriber. When we subscribe to an observable, we pass in a function for the data and another function for errors so that, in case there is some error, we can show some message or process the message in some way.
34. What is Angular Router?
Routing in a single-page frontend application is the task of responding to the changes in the URL made by adding and removing content from the application. This is a complicated task as we first need to intercept a request that changes the browser’s URL as we do not wish for the browser to reload. Then, we need to determine which content to remove and which content to add, and finally, we have to change the browser’s URL as well to show the user the current page they are on.
As we can see, this can be very difficult to implement, especially in multiple applications. That is why Angular comes with a full routing solution for a single-page application. In this, we can define routes with matching components and let Angular handle the routing process.
35. What is REST?
REST in Angular stands for Representational State Transfer. It is an API that works on the request of HTTP. Here, the requested URL points to the data that has to be processed, after which an HTTP function is used to identify the respective operation that has to be performed on the data given. The APIs that follow this method is referred to as RESTful APIs.
36. What is the scope?
A scope is an object in Angular referring to the application model. It is a context for executing expressions. These scopes are organized in a hierarchical form that is similar to the application’s DOM structure. A scope helps in propagating various events and watching expressions.
37. Explain Angular CLI.
Angular CLI is otherwise known as the Angular command-line interface. Angular supports CLI tools that give professionals the ability to use them to add components, deploy them instantly, and perform testing, and many such functions.
38. What is HttpClient, and what are its benefits?
HttpClient is an Angular module used for communicating with a backend service via the HTTP protocol. Usually, in frontend applications, for sending requests, we use the fetch API. However, the fetch API uses promises. Promises are useful, but they do not offer the rich functionalities that observables offer. This is why we use HttpClient in Angular as it returns the data as an observable, which we can subscribe to, unsubscribe to, and perform several operations on using operators. Observables can be converted to promises, and an observable can be created from a promise as well.
39. What is multicasting in Angular?
In Angular, when we are using the HttpClient module to communicate with a backend service and fetch some data, after fetching the data, we can broadcast it to multiple subscribers, all in one execution. This task of responding with data to multiple subscribers is called multicasting. It is specifically useful when we have multiple parts of our applications waiting for some data. To use multicasting, we need to use an RxJS subject. As observables are unicast, they do not allow multiple subscribers. However, subjects do allow multiple subscribers and are multicast.
40. What is a directive in Angular?
A directive in Angular is used to extend the syntax and capabilities of a normal HTML view. Angular directives have special meaning and are understood by the Angular compiler. When Angular begins compiling the TypeScript, CSS, and HTML files into a single JavaScript file, it scans through the entire code and looks for a directive that has been registered. In case it finds a match, then the compiler changes the HTML view accordingly.
Angular is shipped with many directives. However, we can build our directives and let Angular know what they do so that the compiler knows about them and uses them during the compilation step.
41. What is the role of SPA in Angular?
SPA stands for Single Page Application. This technology only maintains one page, index.HTML, even when the URL changes constantly. SPA technology is easy to build and extremely fast in comparison to traditional web technology.
42. Explain different kinds of Angular directives.
There are three kinds of directives in Angular. Let’s discuss them:
- Components: A component is simply a directive with a template. It is used to define a single piece of the user interface using TypeScript code, CSS styles, and the HTML template. When we define a component, we use the component decorated with the @ symbol and pass in an object with a selector attribute. The selector attribute gives the Angular compiler the HTML tag that the component is associated with so that, now, when it encounters this tag in HTML, it knows to replace it with the component template.
- Structural: Structural directives are used to change the structure of a view. For example, if we wish to show or hide some data based on some property, we can do so by using the ngIf directive, or if we wish to add a list of data in the markup, we can use *ngFor, and so on. These directives are called structural directives because they change the structure of the template.
- Attribute: Attribute directives change the appearance or behavior of an element, component, or another directive. They are used as the attributes of elements. Directives such as ngClass and ngStyle are attribute directives.
43. What are the different types of compilers used in Angular?
In Angular, we use two different kinds of compilers:
- Just-in-time (JIT) compiler
- Ahead-of-time (AOT) compiler
Both these compilers are useful but for quite different purposes. The JIT compiler is used to compile TypeScript to JavaScript as our browsers cannot understand TypeScript but only JavaScript. This compilation step is done in a development environment, i.e., when less time is needed to be spent on compilation and more in development to quickly iterate over features. The JIT compiler is used when we use the ng serve or ng build command to serve the app locally or create an uncompressed build of the entire codebase.
On the other hand, the AOT compiler is used to create a minified production build of the entire codebase, which can be used in production. To use the AOT compiler, we have to use the ng build command with the –prod blog: ng build –prod. This instructs the Angular CLI to create an optimized production build of the codebase. This takes a bit more time because several optimizations such as minification can take time, but for production builds, this time can be spared.
44. What is the purpose of the common module in Angular?
In Angular, the common module that is available in the package @angualr/common is a module that encapsulates all the commonly needed features of Angular, such as services, pipes, directives, etc. It contains some sub-modules as well such as the HttpClientModule, which is available in the @angular/common/http package. Because of the modular nature of Angular, its functionalities are stored in small self-contained modules, which can be imported and included in our projects if we need these functionalities.
45. What are the differences between AngularJS and Angular?
AngularJS is the previous version of Angular, which is a complete rewrite, i.e., there are several differences between the two that we can highlight.
- Architecture: AngularJS supports the MVC architecture in which the model contains the business logic; the view shows the information fetched from the models, and the controller manages interactions between the view and the model by fetching data from the model and passing it to the view. On the other hand, Angular architecture is based on components where instead of having separate pieces for logic, presentation, etc., we now have a single self-contained piece of the user interface that can be used in isolation or included in a big project.
- Language: In AngularJS, we could only use JavaScript. However, in Angular, we can use both TypeScript and JavaScript.
- Mobile support: In AngularJS, we do not get mobile browser support out of the box, but in Angular, we do get mobile support for all popular mobile browsers.
46. What are the differences between Angular expressions and JavaScript expressions?
Angular expressions and JavaScript expressions are quite different from each other as, in Angular, we are allowed to write JavaScript in HTML, which we cannot do in plain JavaScript. Also, all expressions in Angular are scoped locally. But, in JavaScript, these expressions are scoped against the global window object. These differences, however, are reconciled when the Angular compiler takes the Angular code we have written and converts it into plain JavaScript, which can then be understood and used by a web browser.
47. What is server-side rendering in Angular?
In a normal Angular application, the browser executes our application, and JavaScript handles all the user interactions. However, because of this, sometimes, if we have a large application with a big bundle size, our page’s load speed is slowed down quite a bit as it needs to download all the files, parse JavaScript, and then execute it. To overcome this slowness, we can use server-side rendering, which allows us to send a fully rendered page from the server that the browser can display and then let the JavaScript code take over any subsequent interactions from the user.
48. What is Angular Universal?
Angular Universal is a package for enabling server-side rendering in Angular applications. We can easily make our application ready for server-side rendering using the Angular CLI. To do this, we need to type the following command:
ng add @nguniversal/express-engine
This allows our Angular application to work well with an ExpressJS web server that compiles HTML pages with Angular Universal based on client requests. This also creates the server-side app module, app.server.module.ts, in our application directory.
49. What is the difference between interpolated content and the content assigned to the innerHTML property of a DOM element?
The angular interpolation happens when in our template we type some JavaScript expression inside double curly braces ‘{{ someExpression() }}’. This is used to add dynamic content to a web page. However, we can do the same by assigning some dynamic content to the innerHTML property of a DOM element. The difference between the two is that, in Angular, the compiler always escapes the interpolated content, i.e., HTML is not interpreted, and the browser displays the code as it is with brackets and symbols, rather than displaying the output of the interpreted HTML. However, in innerHTML, if the content is HTML, then it is interpreted as the HTML code.
50. What are HttpInterceptors in Angular?
HttpInterceptors are part of the @angular/common/HTTP module and are used to inspect and transform HTTP requests and HTTP responses as well. These interceptors are created to perform checks on a request, manipulate the response, and perform cross-cutting concerns, such as logging requests, authenticating a user using a request, using gzip to compress the response, etc. Hopefully, these Angular interview questions in 2021 have helped you get a better grasp of Angular as a framework, as well as its various features and capabilities. These frequently asked questions have been created to give you a better understanding of the kinds of questions asked in interviews, so they will help you in understanding Angular interviews and Angular as a framework. These Angular interview questions with their answers might have whetted your appetite for learning more about the framework. They will surely help you to ace your next job interview.
REACT REACT
1. What is the difference between Virtual DOM and Real DOM?
| Virtual DOM | Real DOM |
| Changes can be made easily | Changes can be expensive |
| Minimal memory wastage | High demand for memory and more wastage |
| JSX element is updated if the element exists | Creates a new DOM every time an element gets updated |
| Cannot update HTML directly | Able to directly manipulate HTML |
| Faster updates | Slow updates |
2. What is React?
React is a widely used JavaScript library that was launched in 2011. It was created by developers at Facebook, and it is primarily used for front-end development. React uses the component-based approach, which ensures to help you build components that possess high reusability.
React is well known for developing and designing complex mobile user interfaces and web applications.
3. What is the meaning of Virtual DOM?
A virtual DOM is a simple JavaScript object that is the exact copy of the corresponding real DOM. It can be considered as a node tree that consists of elements, their attributes, and other properties. Using the render function in React, it creates a node tree and updates it based on the changes that occur in the data model. These changes are usually triggered by users or the actions caused by the system.
Next up among these React interview questions, you need to take a look at some of the important features that React offers.
4. What are some of the important features of React?
React has multiple features that are used for unique purposes. The important ones are as mentioned below:
- React makes use of a single-direction data flow model.
- It deals with complete server-side data processing and handling.
- React uses Virtual DOM that has many advantages of its own.
5. What is the meaning of JSX?
JSX is the abbreviation of JavaScript XML. It is a file that is used in React to bring out the essence of JavaScript to React and use it to its advantage.
It even includes bringing out HTML and the easy syntax of JavaScript. This ensures that the resulting HTML file will have high readability, thereby relatively increasing the performance of the application.
Consider the following example of a JSX:
render(){
return(
<div>
<h1> Hello Intellipaat learners!</h1>
</div>
);
}
6. Can browsers read a JSX file?
No, browsers cannot read JSX files directly. It can only read the objects provided by JavaScript. Now, to make a browser read a JSX file, it has to be transformed to a JavaScript object using JSX transformers, and only then it can be fed into the browser for further use in the pipeline.
7. Why is React widely used today?
React provides users with an ample number of advantages when building an application. Some of them are as follows:
- With React, UI testing becomes very easy.
- React can integrate with Angular and other frameworks easily.
- The high readability index ensures easy understanding.
- React can be used for both client-side and server-side requirements.
- It boosts application performance and overall efficiency.
8. Are there any disadvantages to using React?
There are some limitations when using React as mentioned below:
- Writing code is complicated as it uses JSX and inline template formatting.
- Beginners might find it tough to cope with its syntaxes and methods.
- The library contains a huge repository of information, which might be overwhelming.
- React is a simple library and not a complete framework hence calling for dependencies.
9. Differentiate between Angular and React.
| Comparison Factor | Angular | React |
| Created by | ||
| DOM | Real DOM | Virtual DOM |
| Render Support | Client-side | Server-side |
| Architecture | Full MVC support | Only the view aspect of MVC |
| Data Binding | Unidirectional binding | Two-way binding |
10. What is the meaning of the component-based architecture of React?
In React, components are foundations used to build user interfaces for applications. With the component-based system in place, all of the individual entities become completely reusable and independent of each other. This means that rendering the application is easy and not dependent on the other components of the UI.
11. How does rendering work in React?
Rendering is an important aspect of React as every single component must be rendered. This is done using the render() function. Once the function is called, it returns an element that represents a DOM component.
It is also possible to render more than one HTML element at a time by enclosing the HTML tags and passing them through the render function.
12. What are states in React?
States form to be one of the vital aspects of React. It is considered as a source of data or objects that control aspects such as component behavior and rendering. In React, states are used to easily create dynamic and interactive components.
13. What are props in React?
Props are the shorthand name given to properties in React. Props are read-only components that are immutable in nature. In an application, props follow a hierarchy that is passed down from parent to child components. However, the reverse is not supported. This is done to ensure that there is only a single directional flow in data at all times.
14. What is the use of an arrow function in React?
An arrow function is used to write an expression in React. It allows users to manually bind components easily. The functionality of arrow functions can be very useful when you are working with higher-order functions particularly.
Consider the following example:
//The usual way
render() {
return(
<MyInput onChange={this.handleChange.bind(this) } />
);
}
//Making use of the arrow function
render() {
return(
<MyInput onChange={ (e) => this.handleOnChange(e) } />
);
}
15. What is a higher-order component in React?
Higher-order components (HOCs) are a widely used technique in React for applying concepts that involve the component reusability logic. They are not a native part of the React API and allow users to easily reuse the code and bootstrap abstraction.
HOCs are also used to allow simple sharing of behaviors across all of the components in React, adding more advances to the efficiency and functioning of the application.
16. What is the meaning of create-react-app in React?
The create-react-app in React is a simple command-line interface (CLI) that is used in the creation of React applications, which have no build configuration.
All tools are pre-configured when using the CLI, and this allows users to focus on the code more than on dependencies to develop the application.
The following syntax is used to start a simple project in React:
Create-react-app my-app
17. What are some of the advantages of using create-react-app in React?
Making use of create-react-app is advantageous in the following way:
- Support for JSX, ES6, and flow statements
- Already built and ready auto-prefixed CSS
- Fast interactive testing components
- Live development servers that help in debugging
- Scripts to handle JSS, CSS, and other files
Next up on these React Redux interview questions, you need to understand the meaning of Redux.
18. What is the meaning of Redux?
Redux is used to store the state of the application in a single entity. This simple entity is usually a JavaScript object. Changing states can be done by pushing out actions from the application and writing corresponding objects for them that are used to modify the states.
For example:
{
first_name: ‘John’,
last_name : ‘Kelly’,
age: 25
}
All of the data is retained by Redux (also called a store).
19. What is the difference between props and states?
| Condition | Props | States |
| Changes in child components | Yes | No |
| Parent component changing values | Yes | No |
| Changes inside components | No | Yes |
Next up on this top React interview questions and answers blog, take a look at the questions categorized as intermediate!
20. What are the three phases of a component life cycle in React?
The following are the three phases of a component life cycle:
- Initial rendering: This is the phase that involves the beginning of the journey of the component to the DOM.
- Update: Here, the component can be updated and rendered again if required after it gets added to the DOM.
- Unmounting: The final phase involves the destruction of the component and its eventual removal from the DOM.
21. What are events in React?
Whenever there are actions performed in React, such as hovering the mouse or pressing a key on the keyboard, these actions trigger events. Events then perform set activities as a response to these triggers. Handling an event in React is very similar to that in the DOM architecture.
22. How are events created in React?
Events can be created very easily in React as shown here:
class Display extends React.Component({
show(evt) {
// Code inside
},
render() {
// Render the div with an onClick prop (value is a function)
return (
<div onClick={this.show}>Click Here</div>
);
}
});
23. How is routing in React different from conventional routing?
Differences between the conventional routing and the routing in React can be shown using the following aspects:
- Pages: Each view is considered as a new file in conventional routing while it is considered as a single HTML entity in React.
- Navigation: In conventional routing, users have to move across web pages for viewing. In React, the views are not refreshed as objects are re-issued to create new views.
24. Differentiate between Flux and Redux in React.
| Comparison Factor | Flux | Redux |
| Components | Components connected to Flux in React | Container components directly connect |
| Dispatcher | Has a dispatcher | No dispatcher |
| Number of Stores | Single store | Multiple stores |
| State | Mutable state | Immutable state |
| Storage | Contains state and logic | State and logic are separate |
25. Can AJAX be used with React?
Yes, any AJAX library, such as Axios and jQuery AJAX, can be used with React easily. One important thing is to maintain the states of the components, and here too, the props are passed from the parents to the child components.
Child components still cannot send back props to parents, and this factor greatly increases rendering efficiency when dynamic data is considered.
26. What is the meaning of synthetic events in React?
Synthetic events in React are objects that act as cross-browser wrappers, allowing for the use of native events. This is done to ensure that a variety of browsers can run the API and that the event contains all properties.
27. What are stateful components in React?
Stateful components are entities that store the changes that happen and place them into the memory. Here, the state can be changed, alongside storing information such as past, current, and future changes.
28. What are refs in React?
‘Refs’ is short for references in React. Refs are used to store a reference to a single React element or a React component. This is later returned using the render function.
They are mainly used in the following scenarios:
- To initiate imperative animations
- To join third-party DOM libraries
- To manage focus and apply media playback
29. What are controlled components in React?
Controlled components in React refer to the components that have the ability to maintain their state. The data is completely controlled by the parent component, and the current value is fetched by making use of props. This is done to notify about any change that occurs when using callbacks.
30. Why is a router required in React?
A router is very much necessary in React as it is used to manage multiple routes whenever a user types in a URL. If the route is present in the router for that corresponding URL, then the user is taken to the particular route.
To do this, the router library needs to be added in React. It can be done using the following syntax:
<switch>
<route exact path=’/’ component={Home}/>
<route path=’/posts/:id’ component={Newpost}/>
<route path=’/posts’ component={Post}/>
</switch>
31. What are the components of Redux in React?
Redux consists of four main components as shown below:
- Action: An object that describes the call
- Reducer: The state change storage unit
- Store: the state and object tree storage
- View: Displays data provided by the store
32. What are the advantages of using Redux?
There are many advantages of Redux, and some of them are as given below:
| Organized Approach | Redux requires code to be organized, thereby making it consistent and easy to work with |
| Testing Ability | Redux functions are small and isolated, making the code more independent and testable |
| Tools | Developers can track actions and all of the tools in React using Redux easily |
| Community | Redux has a larger community, helping users with efficient and easy-to-use libraries |
33. What are the disadvantages of using MVC in React?
Among a plethora of advantages of using MVC in React, there are minor problems as stated below:
- A lot of memory wastage occurs.
- DOM manipulation costs a lot.
- The application becomes slow.
- Lots of dependencies are created.
- The complexity of models increases.
Next up among these ReactJS interview questions, you have to understand pure components.
34. What are pure components in React?
Pure components are singular entities that are written in React. They are fast and simple to write and have the ability to replace a component that has only the render() function. This is done to ensure that the performance of the application is good and that the code is kept simple at the same time.
Next up on this top React interview questions blog, take a look at the questions categorized as advanced!
35. What are higher-order components (HOCs) used for?
HOCs are used for a variety of tasks such as:
- Manipulation of props
- State manipulation and abstraction
- Render highjacking
- Code reusing
- Bootstrap abstraction
36. What are keys in React?
Keys are used in React to check all items and to track changes actively. They are used to directly check if an item has been added or removed from a list.
Consider the following syntax:
function List ({ todos }) {
return (
<ul>
{todos.map(({ task, id} ) => <li key={id}>{task}</li>}
</ul>
)
}
37. Differentiate between a controlled component and an uncontrolled component in React.
A controlled component, as the name suggests, is a component over which React has complete control. It is the singular point of data for the forms.
An uncontrolled component is one where the form data gets handled by DOM and not the React component. This is usually done using refs in React.
38. How can you tell React to build in the production mode?
React can be coded to directly build into production by setting the process.env.NODE_ENV variable to production.
Note: When React is in production, warnings and other development features are not shown.
39. What is the difference between cloneElement and createElement in React?
In React, cloneElement is primarily used to clone an element and pass it to new props directly. Whereas, createElement is the entity that JSX gets compiled into. This is also used to create elements in React.
Next up on this top React interview questions and answers blog, take a look at the use of the second argument.
40. What is the use of the second argument that is passed to setState? Is it optional?
When setState is finished, a callback function is invoked, and the components get re-rendered in React.
Yes, it is an optional argument. Since setState is asynchronous, it takes in another callback function. However, in programming practice, it is always good to use another life cycle method instead of this.
Next up on this top React interview questions and answers blog, you need to take a look at binding.
41. Is there a way to avoid the requirement of binding when using React?
Yes, there are two main ways you can use to avoid the need for binding. They are as follows:
- Defining the Event Handler as an Inline Arrow function:
class SubmitButton extends React.Component {
constructor(props) {
super(props);
this.state = {
isFormSubmitted: false
};
}
render() {
return (
<button onClick={() => {
this.setState({ isFormSubmitted: true });
}}>Submit</button>
)
}
}
- Using a function component along with Hooks:
const SubmitButton = () => {
const [isFormSubmitted, setIsFormSubmitted] = useState(false);
return (
<button onClick={() => {
setIsFormSubmitted(true);
}}>Submit</button>
)
};
Also, the Event Handler can be defined as an Arrow function, which is eventually assigned to a Class Field to obtain similar results.
42. What is the StrictMode component used in React?
The StrictMode component when used would benefit users immensely while creating new codebases to understand the components being used.
However, it can fit well in debugging as well because it will help solve the problem faster when it is wrapped with other components, which could be causing the problem.
Next up on these interview questions on React JS, you have to understand how to speed up rendering.
43. What would you do if your React application is rendering slowly?
The cause of slow rendering in React is mostly because of the number of re-render operations, which are sometimes unnecessary. There are two main tools provided by React to help users here:
- memo(): This is used to prevent all of the unnecessary re-rendering carried out by the function components.
- PureComponent: This is used to ensure that the unnecessary re-rendering of class components is avoided.
44. Can you conditionally add attributes to components in React?
Yes, there is a way in which you can add attributes to a React component when certain conditions are met.
React has the ability to omit an attribute if the value passed to it is not true.
Consider the following example:
var condition = true;
var component = (
<div
value="foo"
{ ...( condition && { disabled: true } ) } />
);
45. Why is props passed to the super() function in React?
Props gets passed onto the super() function if a user wishes to access this.props in the constructor.
Consider the following example:
class MyComponent extends React.Component {
constructor(props) {
super(props)
console.log(this.props)
// -> { icon: 'home', … }
}
}
46. What is the difference between using getInitialState and constructors in React?
When using ES6, users must initialize the state in the constructor and the getInitialState method is defined. This is done using React.createClass as shown in the below example:
class MyComponent extends React.Component {
constructor(props) {
super(props);
this.state = { /* initial state */ };
}
}
The above piece of code is equivalent to the following:
var MyComponent = React.createClass({
getInitialState() {
return { /* initial state */ };
},
});
Next up among these interview questions on React JS, you have to know what predefined props are.
47. What are the predefined prop types present in React?
There are five main predefined prop types in React. They are as follows:
- PropTypes.bool
- PropTypes.func
- PropTypes.node
- PropTypes.number
- PropTypes.string
The propTypes can be defined for the user component as shown below:
import PropTypes from 'prop-types';
class User extends React.Component {
render() {
return (
<h1>Welcome, {this.props.name}</h1>
<h2>Age, {this.props.age}
);
}
}
User.propTypes = {
name: PropTypes.string.isRequired,
age: PropTypes.number.isRequired
};
48. What is React Fiber?
React Fiber is a new engine in React. It is the reimplementation core algorithm in React 16.
The main goal of React Fiber is to ensure that there are incremental rendering facilities for the virtual DOM. This increases efficiency when rendering animations, gestures, etc., and also helps in assigning priority to updates based on the requirement, thereby increasing overall efficiency.
49. What are Hooks in React?
Hooks are used to making use of the state and other features without having to explicitly write a class. Hooks were added to the React version, v16.8. The stateful logic can be extracted from a component easily, alongside testing and reusing it. All of this is done without making any changes to the component hierarchy.
50. Do you have any certification to boost your candidature for this React.js role?
With this question, the interviewer is trying to assess if you have any technical experience through learning and implementation. It is always advantageous to have a certification in the technology that you’re applying for.
This creates an impression that you have put your time and effort into learning and implementing the technology. Alongside adding a lot of value to your resume and your knowledge on the topic, it can be used to obtain a well-coveted job in the market!
sql sql
Sameer gaikwad net developer sql mvc NET framework
3. What is SQL?
SQL stands for Structured Query Language. It is the standard language for RDBMS and is useful in handling organized data that has entities or variables with relations between them. SQL is used for communicating with databases.
According to ANSI, SQL is used for maintaining RDBMS and for performing different operations of data manipulation on different types of data by using the features of SQL. Basically, it is a database language that is used for the creation and deletion of databases. It can also be used, among other things, to fetch and modify the rows of a table.
4. What is normalization and its types?
Normalization is used in reducing data redundancy and dependency by organizing fields and tables in databases. It involves constructing tables and setting up relationships between those tables according to certain rules. The redundancy and inconsistent dependency can be removed using these rules to make normalization more flexible.
The different forms of normalization are:
- First Normal Form: If every attribute in a relation is single-valued, then it is in the first normal form. If it contains a composite or multi-valued attribute, then it is in violation of the first normal form.
- Second Normal Form: A relation is said to be in the second normal form if it has met the conditions for the first normal form and does not have any partial dependency, i.e., it does not have a non-prime attribute that relies on any proper subset of any candidate key of the table. Often, the solution to this problem is specifying a single-column primary key.
- Third Normal Form: A relation is in the third normal form when it meets the conditions for the second normal form and there is not any transitive dependency between the non-prime attributes, i.e., all the non-prime attributes are decided only by the candidate keys of the relation and not by other non-prime attributes.
- Boyce-Codd Normal Form: A relation is in the Boyce-Codd normal form or BCNF if it meets the conditions of the third normal form, and for every functional dependency, the left-hand side is a super key. A relation is in BCNF if and only if X is a super key for every nontrivial functional dependency in form X –> Y.
5. What is denormalization?
Denormalization is the opposite of normalization; redundant data is added to speed up complex queries that have multiple tables that need to be joined. Optimization of the read performance of a database is attempted by adding or grouping redundant copies of data.
6. What are Joins in SQL?
Join in SQL is used to combine rows from two or more tables based on a related column between them. There are various types of Joins that can be used to retrieve data, and it depends on the relationship between tables.
There are four types of Joins:
- Inner Join
- Left Join
- Right Join
- Full Join
7. Explain the types of SQL joins.

There are four different types of SQL Joins:
- (Inner) Join: It is used to retrieve the records that have matching values in both the tables that are involved in the join. Inner Join is mostly used to join queries.
SELECT * FROM Table_A JOIN Table_B; SELECT * FROM Table_A INNER JOIN Table_B;
- (Inner) Join: It is used to retrieve the records that have matching values in both the tables that are involved in the join. Inner Join is mostly used to join queries.
 Save
Save
- Left (Outer) Join: Use of left join is to retrieve all the records or rows from the left and the matched ones from the right.
SELECT * FROM Table_A A LEFT JOIN Table_B B ON A.col = B.col;
- Left (Outer) Join: Use of left join is to retrieve all the records or rows from the left and the matched ones from the right.
- Right (Outer) Join: Use of Right join is to retrieve all the records or rows from the right and the matched ones from the left.
SELECT * FROM Table_A A RIGHT JOIN Table_B B ON A.col = B.col;
- Right (Outer) Join: Use of Right join is to retrieve all the records or rows from the right and the matched ones from the left.
- Full (Outer) Join: The use of Full join is to retrieve the records that have a match either in the left table or the right table.
SELECT * FROM Table_A A FULL JOIN Table_B B ON A.col = B.col;
8. What are the subsets of SQL?
SQL queries are divided into four main categories:
- Data Definition Language (DDL)
DDL queries are made up of SQL commands that can be used to define the structure of the database and modify it.- CREATE Creates databases, tables, schema, etc.
- DROP: Drops tables and other database objects
- DROP COLUMN: Drops a column from any table structure
- ALTER: Alters the definition of database objects
- TRUNCATE: Removes tables, views, procedures, and other database objects
- ADD COLUMN: Adds any column to the table schema
- Data Manipulation Language (DML)
These SQL queries are used to manipulate data in a database.- SELECT INTO: Selects data from one table and inserts it into another
- INSERT: Inserts data or records into a table
- UPDATE: Updates the value of any record in the database
- DELETE: Deletes records from a table
- Data Control Language (DCL)
These SQL queries manage the access rights and permission control of the database.- GRANT: Grants access rights to database objects
- REVOKE: Withdraws permission from database objects
- Transaction Control Language (TCL)
TCL is a set of commands that essentially manages the transactions in a database and the changes made by the DML statements. TCL allows statements to be grouped together into logical transactions.- COMMIT: Commits an irreversible transaction, i.e., the previous image of the database prior to the transaction cannot be retrieved
- ROLLBACK: Reverts the steps in a transaction in case of an error
- SAVEPOINT: Sets a savepoint in the transaction to which rollback can be executed
- SET TRANSACTION: Sets the characteristics of the transaction
10. What is a DEFAULT constraint?
Constraints in SQL are used to specify some sort of rules for processing data and limiting the type of data that can go into a table. Now, let us understand what is a default constraint.
A default constraint is used to define a default value for a column so that it is added to all new records if no other value is specified. For example, if we assign a default constraint for the E_salary column in the following table and set the default value to 85000, then all the entries of this column will have the default value of 85000, unless no other value has been assigned during the insertion.

Now, let us go through how to set a default constraint. We will start by creating a new table and adding a default constraint to one of its columns.
Code:
create table stu1(s_id int, s_name varchar(20), s_marks int default 50) select *stu1
Output:

Now, we will insert the records.
Code:
insert into stu1(s_id,s_name) values(1,’Sam’) insert into stu1(s_id,s_name) values(2,’Bob’) insert into stu1(s_id,s_name) values(3,’Matt’) select *from stu1
Output:

11. What is a UNIQUE constraint?
Unique constraints ensure that all the values in a column are different. For example, if we assign a unique constraint to the e_name column in the following table, then every entry in this column should have a unique value.
First, we will create a table.
create table stu2(s_id int unique, s_name varchar(20))
Now, we will insert the records.
insert into stu2 values(1,’Julia’) insert into stu2 values(2,’Matt’) insert into stu2 values(3,’Anne’)
Output:

A PRIMARY KEY constraint will automatically have a UNIQUE constraint. However, unlike a PRIMARY KEY, multiple UNIQUE constraints are allowed per table.
12. What is meant by table and field in SQL?
An organized data in the form of rows and columns is said to be a table. Simply put, it is a collection of related data in a table format.
Here rows and columns are referred to as tuples and attributes, and the number of columns in a table is referred to as a field. In the record, fields represent the characteristics and attributes and contain specific information about the data.
13. What is a primary key?
A primary key is used to uniquely identify all table records. It cannot have NULL values and must contain unique values. Only one primary key can exist in one table, and it may have single or multiple fields, making it a composite key.
Now, we will write a query for demonstrating the use of a primary key for the employee table:
// CREATE TABLE Employee ( ID int NOT NULL, Employee_name varchar(255) NOT NULL, Employee_designation varchar(255), Employee_Age int, PRIMARY KEY (ID) );
14. What is a unique key?
The key that can accept only a null value and cannot accept duplicate values is called a unique key. The role of a unique key is to make sure that all columns and rows are unique.
The syntax for a unique key will be the same as the primary key. So, the query using a unique key for the employee table will be:
// CREATE TABLE Employee ( ID int NOT NULL, Employee_name varchar(255) NOT NULL, Employee_designation varchar(255), Employee_Age int, UNIQUE(ID) );
15. What is the difference between primary key and unique key?
Both primary and unique keys carry unique values but a primary key cannot have a null value, while a unique key can. In a table, there cannot be more than one primary key, but there can be multiple unique keys.
16. What is a foreign key?
A foreign key is an attribute or a set of attributes that reference the primary key of some other table. Basically, a foreign key is used to link together two tables.
Let us create a foreign key for the following table:
CREATE TABLE Orders ( OrderID int NOT NULL, OrderNumber int NOT NULL, PersonID int, PRIMARY KEY (OrderID), FOREIGN KEY (PersonID) REFERENCES Persons(PersonID) )
17. What are the subsets of SQL?
The main subsets of SQL are:
- Data Definition Language (DDL)
- Data Manipulation Language (DML)
- Data Control Language (DCL)
- Transaction Control Language (TCL)
20. What is an index?
Indexes help speed up searching in a database. If there is no index on a column in the WHERE clause, then the SQL Server has to skim through the entire table and check each and every row to find matches, which may result in slow operations in large data.
Indexes are used to find all rows matching with some columns and then to skim through only those subsets of the data to find the matches.
Syntax:
CREATE INDEX INDEX_NAME ON TABLE_NAME (COLUMN)
21. Explain the types of indexes.
Single-column Indexes: A single-column index is created for only one column of a table.
Syntax:
CREATE INDEX index_name ON table_name(column_name);
Composite-column Indexes: A composite-column index is created for two or more columns of a table.
Syntax:
CREATE INDEX index_name ON table_name (column1, column2)
Unique Indexes: A unique index is used for maintaining the data integrity of a table. A unique index does not allow multiple values to be inserted into the table.
Syntax:
CREATE UNIQUE INDEX index ON table_name(column_name)
26. How would you find the second highest salary from the following table?
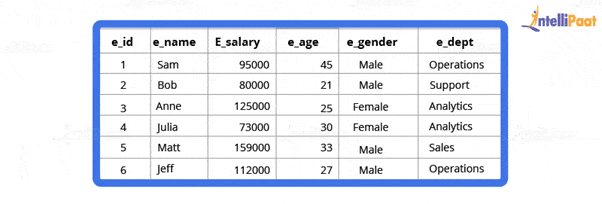
Code:
select * from employee select max(e_salary) from employee where e_salary not in (select max(e_salary) from employee)
Output:
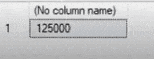
28. State the differences between clustered and non-clustered indexes
- Clustered Index: It is used to sort the rows of data by their key values. A clustered index is like the contents of a phone book. We can open the book at “David” (for “David, Thompson”) and find information for all Davids right next to each other. Since the data is located next to each other, it helps a lot in fetching the data based on range-based queries. A clustered index is actually related to how the data is stored; only one clustered index is possible per table.
- Non-clustered Index: It stores data at one location and indexes at another location. The index has pointers that point to the location of the data. As the indexes in a non-clustered index are stored in a different place, there can be many non-clustered indexes for a table.
Now, we will see the major differences between clustered and non-clustered indexes:
| Parameters | Clustered Index | Non-clustered Index |
| Used For | Sorting and storing records physically in memory | Creating a logical order for data rows; pointers are used for physical data files |
| Methods for Storing | Stores data in the leaf nodes of the index | Never stores data in the leaf nodes of the index |
| Size | Quite large | Comparatively, small |
| Data Accessing | Fast | Slow |
| Additional Disk Space | Not required | Required to store indexes separately |
| Type of Key | By default, the primary key of a table is a clustered index | It can be used with the unique constraint on the table that acts as a composite key |
| Main Feature | Improves the performance of data retrieval | Should be created on columns used in Joins |
33. What is the need for group functions in SQL?
Group functions operate on a series of rows and return a single result for each group. COUNT(), MAX(), MIN(), SUM(), AVG(), and VARIANCE() are some of the most widely used group functions.
35. What is AUTO_INCREMENT?
AUTO_INCREMENT is used in SQL to automatically generate a unique number whenever a new record is inserted into a table.
Since the primary key is unique for each record, this primary field is added as the AUTO_INCREMENT field so that it is incremented when a new record is inserted.
The AUTO-INCREMENT value starts from 1 and is incremented by 1 whenever a new record is inserted.
Syntax:
CREATE TABLE Employee( Employee_id int NOT NULL AUTO-INCREMENT, Employee_name varchar(255) NOT NULL, Employee_designation varchar(255) Age int, PRIMARY KEY (Employee_id) )
36. What is the difference between DELETE and TRUNCATE commands?
- DELETE: This query is used to delete or remove one or more existing tables.
- TRUNCATE: This statement deletes all the data from inside a table.

The difference between DELETE and TRUNCATE commands are as follows:
- TRUNCATE is a DDL command, and DELETE is a DML command.
- With TRUNCATE, we cannot really execute and trigger, while with DELETE, we can accomplish a trigger.
- If a table is referenced by foreign key constraints, then TRUNCATE will not work. So, if we have a foreign key, then we have to use the DELETE command.
The syntax for the DELETE command:
DELETE FROM table_name [WHERE condition];
Example:
select * from stu
Output: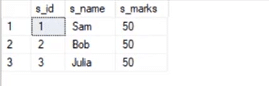
delete from stu where s_name=’Bob’
Output:
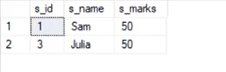
The syntax for the TRUNCATE command:
TRUNCATE TABLE Table_name;
Example:
select * from stu1
Output:
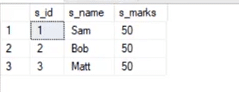
truncate table stu1
Output:
![]()
This deletes all the records from a table.
37. What is the difference between DROP and TRUNCATE commands?
If a table is dropped, all things associated with that table are dropped as well. This includes the relationships defined on the table with other tables, access privileges, and grants that the table has, as well as the integrity checks and constraints.
To create and use the table again in its original form, all the elements associated with the table need to be redefined.
However, if a table is truncated, there are no such problems as mentioned above. The table retains its original structure.
38. What is a “TRIGGER” in SQL?
The trigger can be defined as an automatic process that happens when an event occurs in the database server. It helps to maintain the integrity of the table. The trigger is activated when the commands, such as insert, update, and delete, are given.
The syntax used to generate the trigger function is:
CREATE TRIGGER trigger_name
40. What are the types of relationships in SQL Server databases?
Relationships are developed by interlinking the column of one table with the column of another table. There are three different types of relationships, which are as follows:
- One-to-one relationship
- Many-to-one relationship
- Many-to-many relationship
42. How can you handle expectations in SQL Server?
TRY and CATCH blocks handle exceptions in SQL Server. Put the SQL statement in the TRY block and write the code in the CATCH block to handle expectations. If there is an error in the code in the TRY block, then the control will automatically move to that CATCH block.
43. How many authentication modes are there in SQL Server? And what are they?
Two authentication modes are available in SQL Server. They are:
- Windows Authentication Mode: It allows authentication for Windows but not for SQL Server.
- Mixed Mode: It allows both types of authentication—Windows and SQL Server.
50. What do you know about magic tables in SQL Server?
A magic table can be defined as a provisional logical table that is developed by an SQL Server for tasks such as insert, delete, or update (DML) operations. The operations recently performed on the rows are automatically stored in magic tables. Magic tables are not physical tables; they are just temporary internal tables.
51. What are some common clauses used with SELECT queries in SQL?
There are many SELECT statement clauses in SQL. Some of the most commonly used clauses with SELECT queries are:
- FROM
The FROM clause defines the tables and views from which data can be interpreted. The tables and views listed must exist at the time the question is given. - WHERE
The WHERE clause defines the parameters that are used to limit the contents of the results table. You can test for basic relationships or for relationships between a column and a series of columns using subselects. - GROUP BY
The GROUP BY clause is commonly used for aggregate functions to produce a single outcome row for each set of unique values in a set of columns or expressions. - ORDER BY
The ORDER BY clause helps in choosing the columns on which the table’s result should be sorted. - HAVING
The HAVING clause filters the results of the GROUP BY clause by using an aggregate function.
52. What is wrong with the following SQL query?
SELECT gender, AVG(age) FROM employee WHERE AVG(age)>30 GROUP BY gender
When this command is executed, it gives the following error:
Msg 147, Level 16, State 1, Line 1
Aggregation may not appear in the WHERE clause unless it is in a subquery contained in the HAVING clause or a select list; the column being aggregated is an outer reference.
Msg 147, Level 16, State 1, Line 1 Invalid column name ‘gender’.
This basically means that whenever we are working with aggregate functions and are using the GROUP BY clause, we cannot use the WHERE clause. Therefore, instead of the WHERE clause, we should use the HAVING clause.
When we are using the HAVING clause, the GROUP BY clause should come first, followed by the HAVING clause.
select e_gender, avg(e_age) from employee group by e_gender having avg(e_age)>30
Output:
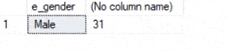
54. What are views? Give an example.
Views are virtual tables used to limit the tables that we want to display. Views are nothing but the result of an SQL statement that has a name associated with it. Since views are not physically present, they take less space to store.
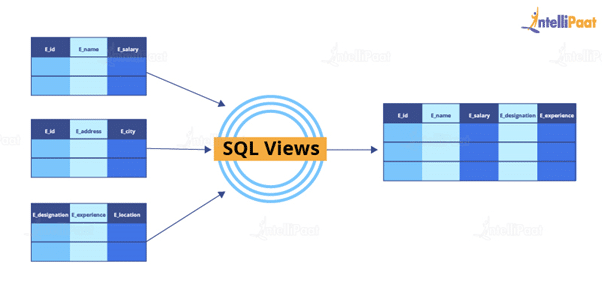
Let us consider an example. In the following employee table, say we want to perform multiple operations on the records with gender “Female”. We can create a view-only table for the female employees from the entire employee table.
Now, let us implement it on SQL Server.
This is the employee table:
select * from employee
Now, we will write the syntax for the view.
Syntax:
create view female_employee as select * from employee where e_gender=’Female’ select * from female_employee
Output:
55. What are the types of views in SQL?
In SQL, the views are classified into four types. They are:
- Simple View: A view that is based on a single table and does not have a GROUP BY clause or other features.
- Complex View: A view that is built from several tables and includes a GROUP BY clause as well as functions.
- Inline View: A view that is built on a subquery in the FROM clause, which provides a temporary table and simplifies a complicated query.
- Materialized View: A view that saves both the definition and the details. It builds data replicas by physically preserving them.
56. What is a stored procedure? Give an example.
A stored procedure is a prepared SQL code that can be saved and reused. In other words, we can consider a stored procedure to be a function consisting of many SQL statements to access the database system. We can consolidate several SQL statements into a stored procedure and execute them whenever and wherever required.
A stored procedure can be used as a means of modular programming, i.e., we can create a stored procedure once, store it, and call it multiple times as required. This also supports faster execution when compared to executing multiple queries.
Syntax:
CREATE PROCEDURE procedure_name AS Sql_statement GO; To execute we will use this: EXEC procedure_name
Example:
We are going to create a stored procedure that will help us extract the age of the employees. create procedure employee_age as select e_age from employee go Now, we will execute it. exec employee_age
Output:

57. Explain Inner Join with an example.
Inner Join basically gives us those records that have matching values in two tables.
Let us suppose that we have two tables, Table A and Table B. When we apply Inner Join on these two tables, we will get only those records that are common to both Table A and Table B.
Syntax:
SELECT columns FROM table1 INNER JOIN table2 ON table1.column_x=table2.column_y;
Example:
select * from employee select * from department
Output:
Now, we will apply Inner Join to both these tables, where the e_dept column in the employee table is equal to the d_name column of the department table.
Syntax:
select employee.e_name, employee.e_dept, department.d_name, department.d_location from employee inner join department on employee.e_dept=department.d_name
Output:

After applying Inner Join, we have only those records where the departments match in both tables. As we can see, the matched departments are Support, Analytics, and Sales.
59. What do you understand about a temporary table? Write a query to create a temporary table
A temporary table helps us store and process intermediate results. Temporary tables are created and can be automatically deleted when they are no longer used. They are very useful in places where temporary data needs to be stored.
Syntax:
CREATE TABLE #table_name(); The below query will create a temporary table: create table #book(b_id int, b_cost int) Now, we will insert the records. insert into #book values(1,100) insert into #book values(2,232) select * from #book
Output:

62. What do you understand by Self Join? Explain using an example
Self Join in SQL is used for joining a table with itself. Here, depending on some conditions, each row of the table is joined with itself and with other rows of the table.
Syntax:
SELECT a.column_name, b.column_name FROM table a, table b WHERE condition
Example:
Consider the customer table given below.
Example:
Consider the customer table given below.
| ID | Name | Age | Address | Salary |
| 1 | Anand | 32 | Ahmedabad | 2,000.00 |
| 2 | Abhishek | 25 | Delhi | 1,500.00 |
| 3 | Shivam | 23 | Kota | 2,000.00 |
| 4 | Vishal | 25 | Mumbai | 6,500.00 |
| 5 | Sayeedul | 27 | Bhopal | 8,500.00 |
| 6 | Amir | 22 | MP | 4,500.00 |
| 7 | Arpit | 24 | Indore | 10,000.00 |
We will now join the table using Self Join:
SQL> SELECT a.ID, b.NAME, a.SALARY FROM CUSTOMERS a, CUSTOMERS b WHERE a.SALARY < b.SALARY;
Output:
| ID | Name | Salary |
| 2 | Anand | 1,500.00 |
| 2 | Abhishek | 1,500.00 |
| 1 | Vishal | 2,000.00 |
| 2 | Vishal | 1,500.00 |
| 3 | Vishal | 2,000.00 |
| 6 | Vishal | 4,500.00 |
| 1 | Sayeedul | 2,000.00 |
| 2 | Sayeedul | 1,500.00 |
| 3 | Sayeedul | 2,000.00 |
| 4 | Sayeedul | 6,500.00 |
| 6 | Sayeedul | 4,500.00 |
| 1 | Amir | 2,000.00 |
| 2 | Amir | 1,500.00 |
| 3 | Amir | 2,000.00 |
| 1 | Arpit | 2,000.00 |
| 2 | Arpit | 1,500.00 |
| 3 | Arpit | 2,000.00 |
| 4 | Arpit | 6,500.00 |
| 5 | Arpit | 8,500.00 |
| 6 | Arpit | 4,500.00 |
63. What is the difference between Union and Union All operators?
The Union operator is used to combine the result set of two or more select statements. For example, the first select statement returns the fish shown in Image A, and the second statement returns the fish shown in Image B. The Union operator will then return the result of the two select statements as shown in Image A U B. If there is a record present in both tables, then we will get only one of them in the final result.
Syntax:
SELECT column_list FROM table1
Union:
SELECT column_list FROM table2
Now, we will execute it in the SQL Server.
These are the two tables in which we will use the Union operator.
select * from student_details1
Union:
select * from student_details2
Output:
The Union All operator gives all the records from both tables including the duplicates.

Let us implement it in the SQL Server.
Syntax:
select * from student_details1
Union All:
select * from student_details2
Output:
64. What is a cursor? How to use a cursor?
A database cursor is a control that allows you to navigate around a table’s rows or documents. It can be referred to as a pointer for a row in a set of rows. Cursors are extremely useful for database traversal operations such as extraction, insertion, and elimination.
- After any variable declaration, DECLARE a cursor. A SELECT statement must always be aligned with the cursor declaration.
- To initialize the result set, OPEN statements must be called before fetching the rows from the result table.
- To grab and switch to the next row in the result set, use the FETCH statement.
- To deactivate the cursor, use the CLOSE expression.
- Finally, use the DEALLOCATE clause to uninstall the cursor description and clear all the resources associated with it.
Here is an example SQL cursor:
DECLARE @name VARCHAR(50) DECLARE db_cursor CURSOR FOR SELECT name From myDB.company WHERE employee_name IN (‘Jay’, ‘Shyam’) OPEN db_cursor FETCH next FROM db_cursor Into @name Close db_cursor DEALLOCATE db_cursor
65. What is the use of the INTERSECT operator?
The INTERSECT operator helps combine two select statements and returns only those records that are common to both the select statements. So, after we get Table A and Table B over here, and if we apply the INTERSECT operator on these two tables, then we will get only those records that are common to the result of the select statements of these two tables.
Syntax:
SELECT column_list FROM table1 INTERSECT SELECT column_list FROM table2
Now, let us take a look at an example for the INTERSECT operator.
select * from student_details1 select * from student_details1
Output:
select * from student_details1 intersect select * from student_details2
Output:

66. How can you copy data from one table into another table?
Here, we have our employee table.
We have to copy this data into another table. For this purpose, we can use the INSERT INTO SELECT operator. Before we go ahead and do that, we will have to create another table that will have the same structure as the above-given table.
Syntax:
create table employee_duplicate( e_id int, e_name varchar(20), e_salary int, e_age int, e_gender varchar(20) e_dept varchar(20) )
For copying the data, we will use the following query:
insert into employee_duplicate select * from employees
Let us take a look at the copied table.
select * from employee_duplicate
Output:
67. What is the difference between BETWEEN and IN operators in SQL?
The BETWEEN operator is used to represent rows based on a set of values. The values may be numbers, text, or dates. The BETWEEN operator returns the total number of values that exist between two specified ranges.
The IN condition operator is used to search for values within a given range of values. If we have more than one value to choose from, then we use the IN operator.
68. Describe how to delete duplicate rows using a single statement but without any table creation.
Let us create an employee table where the column names are ID, NAME, DEPARTMENT, and EMAIL. Below are the SQL scripts for generating the sample data:
CREATE TABLE EMPLOYEE ( ID INT, NAME Varchar(100), DEPARTMENT INT, EMAIL Varchar(100) ) INSERT INTO EMPLOYEE VALUES (1,'Tarun',101,'tarun@intellipaat.com') INSERT INTO EMPLOYEE VALUES (2,'Sabid',102,'sabid@intellipaat.com') INSERT INTO EMPLOYEE VALUES (3,'Adarsh',103,'adarsh@intellipaat.com') INSERT INTO EMPLOYEE VALUES (4,'Vaibhav',104,'vaibhav@intellipaat.com') –These are the duplicate rows: INSERT INTO EMPLOYEE VALUES (5,'Tarun',101,'tarun@intellipaat.com') INSERT INTO EMPLOYEE VALUES (6,'Sabid',102,'sabid@intellipaat.com')
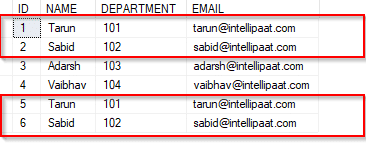
We can see the duplicate rows in the above table.
DELETE e1 FROM EMPLOYEE e1, EMPLOYEE e2 WHERE e1.name = e2.name AND e1.id > e2.id
The SQL query above will delete the rows, where the name fields are duplicated, and it will retain only those unique rows in which the names are unique and the ID fields are the lowest, i.e., the rows with IDs 5 and 6 are deleted, while the rows with IDs 1 and 2 are retained.
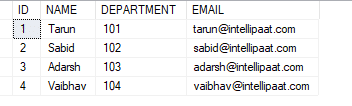
69. Can you identify the employee who has the third-highest salary from the given employee table (with salary-related data)?
Consider the following employee table. In the table, Sabid has the third-highest salary (60,000).
| Name | Salary |
| Tarun | 70,000 |
| Sabid | 60,000 |
| Adarsh | 30,000 |
| Vaibhav | 80,000 |
Below is a simple query to find out the employee who has the third-highest salary. The functions RANK, DENSE RANK, and ROW NUMBER are used to obtain the increasing integer value by imposing the ORDER BY clause in the SELECT statement, based on the ordering of the rows. The ORDER BY clause is necessary when RANK, DENSE RANK, or ROW NUMBER functions are used. On the other hand, the PARTITION BY clause is optional.
WITH CTE AS ( SELECT Name, Salary, RN = ROW_NUMBER() OVER (ORDER BY Salary DESC) FROM EMPLOYEE ) SELECT Name, Salary FROM CTE WHERE RN =3
70. What is the difference between HAVING and WHERE clauses?
The distinction between HAVING and WHERE clauses in SQL is that while the WHERE clause cannot be used with aggregates, the HAVING clause is used with the aggregated data. The WHERE clause works on the data from a row and not with the aggregated data.
Let us consider the employee table below.
| Name | Department | Salary |
| Tarun | Production | 50,000 |
| Tarun | Testing | 60,000 |
| Sabid | Marketing | 70,000 |
| Adarsh | Production | 80,000 |
| Vaibhav | Testing | 90,000 |
The following will select the data on a row-by-row basis:
SELECT Name, Salary FROM Employee WHERE Salary >=50000
Output:
| Name | Salary |
| Tarun | 50,000 |
| Tarun | 60,000 |
| Sabid | 70,000 |
| Adarsh | 80,000 |
| Vaibhav | 90,000 |
The HAVING clause, on the other hand, operates on the aggregated results.
SELECT Department, SUM(Salary) AS total FROM Employee GROUP BY Department
Output:
| Department | Total |
| Marketing | 70,000 |
| Production | 130,000 |
| Testing | 150,000 |
Now, let us see the output when we apply HAVING to the above query.
SELECT Department, SUM(Salary) AS total FROM Employee GROUP BY Department HAVING SUM(Salary)>70000
Output:
| Department | Total |
| Production | 130,000 |
| Testing | 150,000 |
71. Explain database white box testing and black box testing.
The white box testing method mainly deals with the internal structure of a particular database, where users hide specification details. The white box testing method involves the following:
- As the coding error can be detected by testing the white box, it can eliminate internal errors.
- To check for the consistency of the database, it selects the default table values.
- This method verifies the referential integrity rule.
- It helps perform the module testing of database functions, triggers, views, and SQL queries.
The black box testing method generally involves interface testing, followed by database integration. The black box testing method involves the following:
- Mapping details
- Verification of incoming data
- Verification of outgoing data from the other query functions
72. How can you create empty tables with the same structure as another table?
This can be achieved by fetching the records of one table into a new table using the INTO operator while fixing a WHERE clause to be false for all records. In this way, SQL prepares the new table with a duplicate structure to accept the fetched records. However, there are no records that will get fetched due to the WHERE clause in action. Therefore, nothing is inserted into the new table, thus creating an empty table.
SELECT * INTO Students_copy FROM Students WHERE 1 = 2;
MVC MVC
MVC is a software architecture pattern for developing web applications. It is handled by three objects, Model, View, and Controller.
2) What does Model-View-Controller represent in an MVC application?
In an MVC model,
- Model– It represents the application data domain. In other words, an application’s business logic is contained within the model and is responsible for maintaining data.
- View– It represents the user interface with which end-users communicate. In short, all the user interface logic is contained within View.
- Controller- It is the controller that answers the user’s actions. Based on the user actions, the respective controller responds within the model and chooses a view to render that displays the user interface. The user input logic is contained within the controller.
2. Explain what is MVC?
MVC is an abbreviation for Model, View, and Controller. The MVC architectural pattern separates an application into three components – Model, View, and Controller. In this pattern, the model represents the shape of the data and business logic. It maintains and preserves the data of the application. Model objects retrieve and store model states in a database. The view is basically and technically a user interface. The view segment displays the data-using model to the user and also enables them to modify the data. The controller is the part, which handles the user request.
4) What are the different return types of a controller action method
Here are different return types of a controller action method:
- View Result
- JavaScript Result
- Redirect Result
- JSON Result
- Content Result
4. What are the advantages of MVC?
The benefits or advantages of MVC are as follows:
Multiple view support: Because of the separation of the model from the view, the user interface can display multiple views of the same data at the same time.
Change Accommodation: User interfaces tend to change more frequently than business rules.
SoC – Separation of Concerns: Separation of Concerns is one of the core advantages of ASP.NET MVC. The MVC framework provides a clean separation of the UI, Business Logic, Model, or Data.
More Control: The ASP.NET MVC framework provides more control over HTML, JavaScript, and CSS than the traditional WebForms.
Testability: This framework provides better testability of the Web Application and good support for test-driven development too.
Lightweight: MVC framework doesn’t use View State and that reduces the bandwidth of the requests to an extent.
Here is the role of components Presentation, Abstraction, and Control in MVC:
- Presentation: It is the visual representation of a specific abstraction within the application
- Abstraction: It is the business domain functionality within the application
- Control: It is a component that keeps consistency between the abstraction within the system and their presentation to the user in addition to communicating with other controls within the system
13) What is routing and three segments?
Routing helps you to decide on a URL structure and map the URL with the Controller.
The three segments that are important for routing are:
- ControllerName
- ActionMethodName
- Parameter
15) How can you navigate from one view to other view using a hyperlink?
By using the “ActionLink” method as shown in the below code. The below code will make a simple URL that helps to navigate to the “Home” controller and invoke the “GotoHome” action.
Collapse / Copy Code
<%= Html.ActionLink("Home", "Gotohome") %>16) How are sessions maintained in MVC?
Sessions can be maintained in MVC in three ways: tempdata, viewdata, and viewbag.
17) What is the difference between Temp data, View data, and View Bag?
- Temp data: It helps to maintain data when you shift from one controller to another controller.
- View data: It helps to maintain data when you move from controller to view.
- View Bag: It’s a dynamic wrapper around view data.
13. What is Partial View in MVC?
A partial view is a chunk of HTML that can be safely inserted into an existing DOM. Most commonly, partial views are used to componentize Razor views and make them easier to build and update. It can also be returned directly from controller methods. In this case, the browser still receives text/HTML content but not necessarily HTML content that makes up an entire page. As a result, if a URL that returns a partial view is directly invoked from the address bar of a browser, an incomplete page may be displayed. This may be something like a page that misses the title, script, and style sheets.
19) How can you implement Ajax in MVC?
In MVC, Ajax can be implemented in two ways
- Ajax libraries
- Jquery
20) What is the difference between “ActionResult” and “ViewResult”?
“ActionResult” is an abstract class while “ViewResult” is derived from “AbstractResult” class. “ActionResult” has a number of derived classes like “JsonResult”, “FileStreamResult” and “ViewResult”.
“ActionResult” is best if you are deriving different types of views dynamically.
21) How can you send the result back in JSON format in MVC?
In order to send the result back in JSON format in MVC, you can use “JSONRESULT” class.
22) What is the difference between View and Partial View?
Here is the difference between View and Partial View
| View | Partial View |
|---|---|
| It contains the layout page | It does not contain the layout page |
| Before any view is rendered, viewstart page is rendered | Partial view does not verify for a viewstart.cshtml. We cannot put common code for a partial view within the viewStart.cshtml.page |
| View might have markup tags like body, html, head, title, meta etc. | Partial view is designed specially to render within the view, and just because of that it does not consist any markup |
| View is not lightweight as compare to Partial View | We can pass a regular view to the RenderPartial method |
23) What are the types of results in MVC?
In MVC, there are twelve types of results in where “ActionResult” class is the main class while the 11 are their sub-types:
- ViewResult
- PartialViewResult
- EmptyResult
- RedirectResult
- RedirectToRouteResult
- JsonResult
- JavaScriptResult
- ContentResult
- FileContentResult
- FileStreamResult
- FilePathResult
26) What is the order of the filters that get executed if multiple filters are implemented?
The filter order would be like this:
- Authorization filters
- Action filters
- Response filters
- Exception filters
For razor views, the file extensions are
- .cshtml: If C# is the programming language
- .vbhtml: If VB is the programming language
37) What is the difference between Web Forms and MVC?
Here is a difference between Web Forms and MVC:
| Parameters | Web Forms | MVC |
|---|---|---|
| Model | Asp.Net Web Forms follow event-driven development model. | Asp.Net MVC uses MVC pattern-based development model. |
| Used Since | Been around since 2002 | It was first released in 2009 |
| Support for View state | Asp.Net Web Forms supports view state for state management at the client-side. | .Net MVC doesn’t support view state. |
| URL type | Asp.Net Web Forms has file-based URLs. It means file name exists in the URLs, and they must exist physically. | Asp.Net MVC has route-based URLs that means URLs are redirected to controllers and actions. |
| Syntax | Asp.Net MVC follows Web Forms Syntax. | Asp.Net MVC follows the customizable syntax. |
| View type | Web Forms views are tightly coupled to Code behind(ASPX-CS), i.e., logic. | MVC Views and logic are always kept separately. |
| Consistent look and feels | It has master pages for a consistent look. | Asp.Net MVC has layouts for a consistent look. |
| Code Reusability | Web Forms offers User controls for code re-usability. | Asp.Net MVC offers partial views for code re-usability. |
| Control for HTML | Less control over rendered HTML. | Full control over HTML |
| State management | Automatic state management of controls. | Manual state management. |
| TDD support | Weak or custom TDD required. | Encourages and includes TDD! |
6. How to maintain session in MVC?
The session can be maintained in MVC by three ways temp data, viewdata, and view bag.
8. What does the MVC Pattern define with 3 logical layers?
The MVC model defines web applications with 3 logic layers:
The business layer (Model logic)
The display layer (View logic)
The input control (Controller logic)
The Model is the part of the application, which only handles the logic for the application data. Regularly, the model objects retrieve data (as well as store data) from a database. The View is the part of the application, which takes care of the display of the data. Most often, the views are created from the model data, although there are other, more complicated methods of creating views. The Controller, as the name implies, is the part of the application that handles user interaction.
10. What is ASP.NET MVC?
ASP.NET MVC is a web application Framework. It is a lightweight and highly testable Framework. MVC separates an application into three components — Model, View, and Controller.
11. What is MVC Routing?
The URLs in ASP.NET MVC are mapped to action methods and controller instead of physical files of the system. To accurately map action methods and controller to URLs, the routing engine forms appropriate routes. Using this, the controllers can handle specific requests.

15. What is the use of ViewModel in MVC?
ViewModel is a plain class with properties, which is used to bind it to a strongly-typed view. ViewModel can have the validation rules defined for its properties using data annotation.
18. Explain the concept of Razor in ASP.NET MVC?
ASP.NET MVC has always supported the concept of “view engines” – which are the pluggable modules that implement different template syntax options. The “default” view engine for ASP.NET MVC uses the same .aspx/.ascx/. master file templates as ASP.NET WebForms. Other popular ASP.NET MVC view engines are Spart & Nhaml. Razor is the new view engine introduced by MVC 3.
19. Explain the concept of Default Route in MVC
Default Route: The default ASP.NET MVC project templates add a generic route that uses the following URL convention to break the URL for a given request into three named segments.
URL: "{controller}/{action}/{id}"
20. What is GET and POST Action types?
GET Action Type: GET is used to request data from a specified resource. With all the GET requests, we pass the URL, which is compulsory; however, it can take up the following overloads.
POST Action Type: The POST is used to submit data to be processed to a specified resource. With all the POST requests, we pass the URL, which is essential and the data. However, it can take up the following overloads.
21. How does View Data differ from View Bag in MVC?
View Data | View Bag |
ViewData is used to pass data from a controller to view | ViewBag is also used to pass data from the controller to the respective view. |
It is available for the current request only. | It is also available for the current request only. |
Requires typecasting for complex data types and checks for null values to avoid error | Doesn’t require typecasting for the complex data type. |
If redirection occurs, then its value becomes null. | If redirection occurs, then its value becomes null. |
25. How can we implement validation in MVC?
We can easily implement validation in the MVC application by using the validators defined in the System.ComponentModel.DataAnnotations namespace. There are different types of validators as follows:
Required
DataType
Range
StringLength
28. What is the use of Keep and Peek in “TempData”?
Once “TempData” is read in the current request, it’s not available in the subsequent request. If we want “TempData” to be read and also available in the subsequent request then after reading we need to call “Keep” method as shown in the code below.
1 2 | @TempData["MyData"];TempData.Keep("MyData"); |
The more shortcut way of achieving the same is by using “Peek”. This function helps to read as well advices MVC to maintain “TempData” for the subsequent request.
1 | string str = TempData.Peek("Td").ToString(); |
29. What is WebAPI?
HTTP is the most used protocol. Since many years, the browser was the most preferred client by which we consumed data exposed over HTTP. But as years passed by, client variety started spreading out. We had demanded to consume data on HTTP from clients like mobile, JavaScript, Windows applications, etc.
For satisfying the broad range of clients, REST was the proposed approach. WebAPI is the technology by which you can expose data over HTTP following REST principles.
30. How can we detect that an MVC controller is called by POST or GET?
To detect if the call on the controller is a POST action or a GET action we can use the Request.HttpMethod property as shown in the below code snippet.
1 2 3 4 5 6 7 8 | public ActionResult SomeAction(){if (Request.HttpMethod == "POST"){return View("SomePage");}else{return View("SomeOtherPage");}} |
31. What are the main Razor Syntax Rules
Following are the rules for main Razor Syntax:
Razor code blocks are enclosed in @{ … }
Inline expressions (variables and functions) start with @
Code statements end with a semicolon
Variables are declared with the var keyword
Strings are enclosed with quotation marks
C# code is case sensitive
C# files have the extension .cshtml
32. How do you implement Forms authentication in MVC?
Authentication is giving access to the user for a specific service by verifying his/her identity using his/her credentials like username and password or email and password. It assures that the correct user is authenticated or logged in for a specific service and the right service has been provided to the specific user based on their role.
33. Can you explain RenderBody and RenderPage in MVC?
RenderBody is like ContentPlaceHolder in web forms. This will exist in layout page and it will render the child pages/views. Layout page will have only one RenderBody() method. RenderPage also exists in Layout page and multiple RenderPage() can be there in the Layout page.
34. What are Non Action methods in MVC?
In MVC all public methods have been treated as Actions. So if you are creating a method and if you do not want to use it as an action method then the method has to be decorated with “NonAction” attribute as shown below –
1 2 3 4 | [NonAction]public void TestMethod(){// Method logic} |
35. How to perform Exception Handling in MVC?
In the controller, you can override the “OnException” event and set the “Result” to the view name which you want to invoke when an error occurs. In the below code you can see we have set the “Result” to a view named as “Error”.
We have also set the exception so that it can be displayed inside the view.
1 2 3 4 5 6 7 8 9 10 11 12 | public class HomeController : Controller{protected override void OnException(ExceptionContext filterContext){Exception ex = filterContext.Exception;filterContext.ExceptionHandled = true;var model = new HandleErrorInfo(filterContext.Exception, "Controller","Action");filterContext.Result = new ViewResult(){ViewName = "Error",ViewData = new ViewDataDictionary(model)};}} |
36. Which is a better fit, Razor or ASPX?
As per Microsoft, Razor is more preferred because it’s lightweight and has simple syntax’s.
37. What is Code Blocks in Views?
Unlike code expressions that are evaluated and sent to the response, it is the blocks of code that are executed. This is useful for declaring variables which we may be required to be used later.
1 2 3 4 | @{int x = 123;string y = “aa”;} |
38. Why use Html.Partial in MVC?
This method is used to render the specified partial view as an HTML string. This method does not depend on any action methods. We can use this like below –
1 | @Html.Partial(“TestPartialView”) |
40. How can we navigate from one view to another using a hyperlink?
By using the ActionLink the method you can navigate. The below code will create a simple URL that helps to navigate to the “Home” controller and invoke the Gotohome action.
1 | <%= Html.ActionLink("Home","Gotohome") %> |
.
Node.js is a super popular server-side platform that more and more organizations are using. If you are preparing for a career change and have an upcoming job interview, it’s always a good idea to prepare and brush up on your interview skills beforehand. Although there are a few commonly asked Node.js interview questions that pop up during all types of interviews, we also recommend that you prepare by focusing on exclusive questions to your specific industry.
We have compiled a comprehensive list of common Node.js interview questions that come up often in interviews and the best ways to answer these questions. This will also help you understand the fundamental concepts of Node.js.
Get All Your Questions Answered Here!
Caltech PGP Full Stack DevelopmentExplore ProgramThis section will provide you with the Basic Node.js interview questions which will primarily help freshers.
1. What is Node.js? Where can you use it?
Node.js is an open-source, cross-platform JavaScript runtime environment and library to run web applications outside the client’s browser. It is used to create server-side web applications.
Node.js is perfect for data-intensive applications as it uses an asynchronous, event-driven model. You can use I/O intensive web applications like video streaming sites. You can also use it for developing: Real-time web applications, Network applications, General-purpose applications, and Distributed systems.
2. Why use Node.js?
Node.js makes building scalable network programs easy. Some of its advantages include:
- It is generally fast
- It rarely blocks
- It offers a unified programming language and data type
- Everything is asynchronous
- It yields great concurrency
3. How does Node.js work?
A web server using Node.js typically has a workflow that is quite similar to the diagram illustrated below. Let’s explore this flow of operations in detail.
- Clients send requests to the webserver to interact with the web application. Requests can be non-blocking or blocking:
- Querying for data
- Deleting data
- Updating the data
- Node.js retrieves the incoming requests and adds those to the Event Queue
- The requests are then passed one-by-one through the Event Loop. It checks if the requests are simple enough not to require any external resources
- The Event Loop processes simple requests (non-blocking operations), such as I/O Polling, and returns the responses to the corresponding clients
A single thread from the Thread Pool is assigned to a single complex request. This thread is responsible for completing a particular blocking request by accessing external resources, such as computation, database, file system, etc.
Once the task is carried out completely, the response is sent to the Event Loop that sends that response back to the client.
4. Why is Node.js Single-threaded?
Node.js is single-threaded for async processing. By doing async processing on a single-thread under typical web loads, more performance and scalability can be achieved instead of the typical thread-based implementation.
5. If Node.js is single-threaded, then how does it handle concurrency?
The Multi-Threaded Request/Response Stateless Model is not followed by the Node JS Platform, and it adheres to the Single-Threaded Event Loop Model. The Node JS Processing paradigm is heavily influenced by the JavaScript Event-based model and the JavaScript callback system. As a result, Node.js can easily manage more concurrent client requests. The event loop is the processing model's beating heart in Node.js.
6. Explain callback in Node.js.
A callback function is called after a given task. It allows other code to be run in the meantime and prevents any blocking. Being an asynchronous platform, Node.js heavily relies on callback. All APIs of Node are written to support callbacks.
7. What are the advantages of using promises instead of callbacks?
- The control flow of asynchronous logic is more specified and structured.
- The coupling is low.
- We've built-in error handling.
- Improved readability.
8. How would you define the term I/O?
- The term I/O is used to describe any program, operation, or device that transfers data to or from a medium and to or from another medium
- Every transfer is an output from one medium and an input into another. The medium can be a physical device, network, or files within a system

9. How is Node.js most frequently used?
Node.js is widely used in the following applications:
- Real-time chats
- Internet of Things
- Complex SPAs (Single-Page Applications)
- Real-time collaboration tools
- Streaming applications
- Microservices architecture
10. Explain the difference between frontend and backend development?
|
Front-end |
Back-end |
|
Frontend refers to the client-side of an application |
Backend refers to the server-side of an application |
|
It is the part of a web application that users can see and interact with |
It constitutes everything that happens behind the scenes |
|
It typically includes everything that attributes to the visual aspects of a web application |
It generally includes a web server that communicates with a database to serve requests |
|
HTML, CSS, JavaScript, AngularJS, and ReactJS are some of the essentials of frontend development |
Java, PHP, Python, and Node.js are some of the backend development technologies |
11. What is NPM?
NPM stands for Node Package Manager, responsible for managing all the packages and modules for Node.js.
Node Package Manager provides two main functionalities:
- Provides online repositories for node.js packages/modules, which are searchable on search.nodejs.org
- Provides command-line utility to install Node.js packages and also manages Node.js versions and dependencies
12. What are the modules in Node.js?
Modules are like JavaScript libraries that can be used in a Node.js application to include a set of functions. To include a module in a Node.js application, use the require() function with the parentheses containing the module's name.
Node.js has many modules to provide the basic functionality needed for a web application. Some of them include:
|
Core Modules |
Description |
|
HTTP |
Includes classes, methods, and events to create a Node.js HTTP server |
|
util |
Includes utility functions useful for developers |
|
fs |
Includes events, classes, and methods to deal with file I/O operations |
|
url |
Includes methods for URL parsing |
|
query string |
Includes methods to work with query string |
|
stream |
Includes methods to handle streaming data |
|
zlib |
Includes methods to compress or decompress files |
13. What is the purpose of the module .Exports?
In Node.js, a module encapsulates all related codes into a single unit of code that can be parsed by moving all relevant functions into a single file. You may export a module with the module and export the function, which lets it be imported into another file with a needed keyword.14. Why is Node.js preferred over other backend technologies like Java and PHP?
Some of the reasons why Node.js is preferred include:
- Node.js is very fast
- Node Package Manager has over 50,000 bundles available at the developer’s disposal
- Perfect for data-intensive, real-time web applications, as Node.js never waits for an API to return data
- Better synchronization of code between server and client due to same code base
- Easy for web developers to start using Node.js in their projects as it is a JavaScript library
15. What is the difference between Angular and Node.js?
|
Angular |
Node.js |
|
It is a frontend development framework |
It is a server-side environment |
|
It is written in TypeScript |
It is written in C, C++ languages |
|
Used for building single-page, client-side web applications |
Used for building fast and scalable server-side networking applications |
|
Splits a web application into MVC components |
Generates database queries |
Also Read: What is Angular?
16. Which database is more popularly used with Node.js?
MongoDB is the most common database used with Node.js. It is a NoSQL, cross-platform, document-oriented database that provides high performance, high availability, and easy scalability.
17. What are some of the most commonly used libraries in Node.js?
There are two commonly used libraries in Node.js:
- ExpressJS - Express is a flexible Node.js web application framework that provides a wide set of features to develop web and mobile applications.
- Mongoose - Mongoose is also a Node.js web application framework that makes it easy to connect an application to a database.
18. What are the pros and cons of Node.js?
|
Node.js Pros |
Node.js Cons |
|
Fast processing and an event-based model |
Not suitable for heavy computational tasks |
|
Uses JavaScript, which is well-known amongst developers |
Using callback is complex since you end up with several nested callbacks |
|
Node Package Manager has over 50,000 packages that provide the functionality to an application |
Dealing with relational databases is not a good option for Node.js |
|
Best suited for streaming huge amounts of data and I/O intensive operations |
Since Node.js is single-threaded, CPU intensive tasks are not its strong suit |
19. What is the command used to import external libraries?
The “require” command is used for importing external libraries. For example - “var http=require (“HTTP”).” This will load the HTTP library and the single exported object through the HTTP variable.
Now that we have covered some of the important beginner-level Node.js interview questions let us look at some of the intermediate-level Node.js interview questions.
![]()
Node.js Interview Questions and Answers For Intermediate Level
20. What does event-driven programming mean?
An event-driven programming approach uses events to trigger various functions. An event can be anything, such as typing a key or clicking a mouse button. A call-back function is already registered with the element executes whenever an event is triggered.
21. What is an Event Loop in Node.js?
Event loops handle asynchronous callbacks in Node.js. It is the foundation of the non-blocking input/output in Node.js, making it one of the most important environmental features.
22. Differentiate between process.nextTick() and setImmediate()?
The distinction between method and product. This is accomplished through the use of nextTick() and setImmediate(). next Tick() postpones the execution of action until the next pass around the event loop, or it simply calls the callback function once the event loop's current execution is complete, whereas setImmediate() executes a callback on the next cycle of the event loop and returns control to the event loop for any I/O operations.
23. What is an EventEmitter in Node.js?
- EventEmitter is a class that holds all the objects that can emit events
- Whenever an object from the EventEmitter class throws an event, all attached functions are called upon synchronously

24. What are the two types of API functions in Node.js?
The two types of API functions in Node.js are:
- Asynchronous, non-blocking functions
- Synchronous, blocking functions
25. What is the package.json file?
The package.json file is the heart of a Node.js system. This file holds the metadata for a particular project. The package.json file is found in the root directory of any Node application or module
This is what a package.json file looks like immediately after creating a Node.js project using the command: npm init
You can edit the parameters when you create a Node.js project.

26. How would you use a URL module in Node.js?
The URL module in Node.js provides various utilities for URL resolution and parsing. It is a built-in module that helps split up the web address into a readable format.

27. What is the Express.js package?
Express is a flexible Node.js web application framework that provides a wide set of features to develop both web and mobile applications
28. How do you create a simple Express.js application?
- The request object represents the HTTP request and has properties for the request query string, parameters, body, HTTP headers, and so on
- The response object represents the HTTP response that an Express app sends when it receives an HTTP request

29. What are streams in Node.js?
Streams are objects that enable you to read data or write data continuously.
There are four types of streams:
Readable – Used for reading operations
Writable − Used for write operations
Duplex − Can be used for both reading and write operations
Transform − A type of duplex stream where the output is computed based on input
30. How do you install, update, and delete a dependency?

31. How do you create a simple server in Node.js that returns Hello World?

- Import the HTTP module
- Use createServer function with a callback function using request and response as parameters.
- Type “hello world."
- Set the server to listen to port 8080 and assign an IP address
32. Explain asynchronous and non-blocking APIs in Node.js.
- All Node.js library APIs are asynchronous, which means they are also non-blocking
- A Node.js-based server never waits for an API to return data. Instead, it moves to the next API after calling it, and a notification mechanism from a Node.js event responds to the server for the previous API call
33. How do we implement async in Node.js?
As shown below, the async code asks the JavaScript engine running the code to wait for the request.get() function to complete before moving on to the next line for execution.
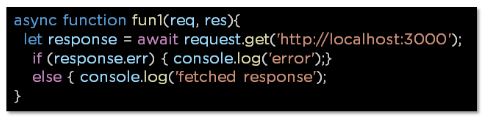
34. What is a callback function in Node.js?
A callback is a function called after a given task. This prevents any blocking and enables other code to run in the meantime.
In the last section, we will now cover some of the advanced-level Node.js interview questions.
Node.js Interview Questions and Answers For Experienced Professionals
This section will provide you with the Advanced Node.js interview questions which will primarily help experienced professionals.
35. What is REPL in Node.js?
REPL stands for Read Eval Print Loop, and it represents a computer environment. It’s similar to a Windows console or Unix/Linux shell in which a command is entered. Then, the system responds with an output

36. What is the control flow function?
The control flow function is a piece of code that runs in between several asynchronous function calls.
37. How does control flow manage the function calls?

38. What is the difference between fork() and spawn() methods in Node.js?
|
fork() |
spawn() |
|
fork() is a particular case of spawn() that generates a new instance of a V8 engine. |
Spawn() launches a new process with the available set of commands. |
|
Multiple workers run on a single node code base for multiple tasks. |
This method doesn’t generate a new V8 instance, and only a single copy of the node module is active on the processor. |
39. What is the buffer class in Node.js?
Buffer class stores raw data similar to an array of integers but corresponds to a raw memory allocation outside the V8 heap. Buffer class is used because pure JavaScript is not compatible with binary data
40. What is piping in Node.js?
Piping is a mechanism used to connect the output of one stream to another stream. It is normally used to retrieve data from one stream and pass output to another stream
41. What are some of the flags used in the read/write operations in files?

42. How do you open a file in Node.js?
![]()
43. What is callback hell?
- Callback hell, also known as the pyramid of doom, is the result of intensively nested, unreadable, and unmanageable callbacks, which in turn makes the code harder to read and debug
- improper implementation of the asynchronous logic causes callback hell
44. What is a reactor pattern in Node.js?
A reactor pattern is a concept of non-blocking I/O operations. This pattern provides a handler that is associated with each I/O operation. As soon as an I/O request is generated, it is then submitted to a demultiplexer
45. What is a test pyramid in Node.js?

46. For Node.js, why does Google use the V8 engine?
The V8 engine, developed by Google, is open-source and written in C++. Google Chrome makes use of this engine. V8, unlike the other engines, is also utilized for the popular Node.js runtime. V8 was initially intended to improve the speed of JavaScript execution within web browsers. Instead of employing an interpreter, V8 converts JavaScript code into more efficient machine code to increase performance. It turns JavaScript code into machine code during execution by utilizing a JIT (Just-In-Time) compiler, as do many current JavaScript engines such as SpiderMonkey or Rhino (Mozilla).
47. Describe Node.js exit codes.

48. Explain the concept of middleware in Node.js.
Middleware is a function that receives the request and response objects. Most tasks that the middleware functions perform are:
- Execute any code
- Update or modify the request and the response objects
- Finish the request-response cycle
- Invoke the next middleware in the stack
49. What are the different types of HTTP requests?
HTTP defines a set of request methods used to perform desired actions. The request methods include:
GET: Used to retrieve the data
POST: Generally used to make a change in state or reactions on the server
HEAD: Similar to the GET method, but asks for the response without the response body
DELETE: Used to delete the predetermined resource
50. How would you connect a MongoDB database to Node.js?
To create a database in MongoDB:
- Start by creating a MongoClient object
- Specify a connection URL with the correct IP address and the name of the database you want to create
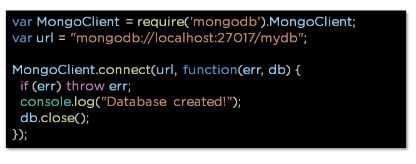
51. What is the purpose of NODE_ENV?
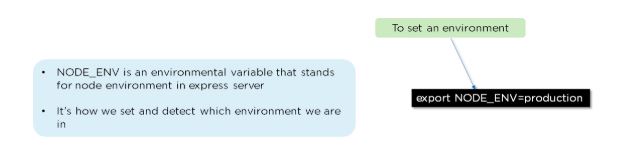
52. List the various Node.js timing features.
As you prepare for your upcoming job interview, we hope that this comprehensive guide has provided more insight into what types of questions you’ll be asked.

53. What is WASI, and why is it being introduced?
The WASI class implements the WASI system called API and extra convenience methods for interacting with WASI-based applications. Every WASI instance represents a unique sandbox environment. Each WASI instance must specify its command-line parameters, environment variables, and sandbox directory structure for security reasons.




0 Comments